We run the series of Badger Seminars to bring together world-renowned experts in order to advance the field of life-long learning, meta-learning, multi-agent learning and other directions that we believe are relevant for building generally intelligent agents.

Oranžérie: the office of GoodAI and location of the seminars
Previous editions
Badger Seminar 2021: Beyond Life-long Learning via Modular Meta-Learning
The goal of GoodAI’s Badger architecture and the desired outcome of our research is the creation of a lifelong learning system that is able to gradually accumulate knowledge and effectively re-use such knowledge for the learning of new skills. Such a system should be able to continually adapt and learn to solve a growing, open-ended range of new and unseen tasks and operate in environments of increasing complexity.
At this seminar we discussed possible pathways to designing such a system through careful meta-learning of a distributed modular learning system coupled with the appropriate minimum viable environment/dataset, cultivating the necessary inductive biases to afford the discovery of a lifelong learner with such properties.
The aim of this seminar was to:
- Bring together the participants of GoodAI Grants program, as well as invited guests and the GoodAI team, who share similar research goals
- Discuss in depth the preliminary findings and experimental results related to the awarded grants and state of GoodAI’s Badger architecture
- Share perspectives on several areas of focus:
- Lifelong & Open-Ended Learning
- Meta-Learning & Modular Meta-Learning
- Learned Communication
- Optimization in Modular Systems; Learned Optimizers
- Program Composition and Synthesis
- Multi-Agent Reinforcement Learning
- Graph Neural Networks
Where and when?
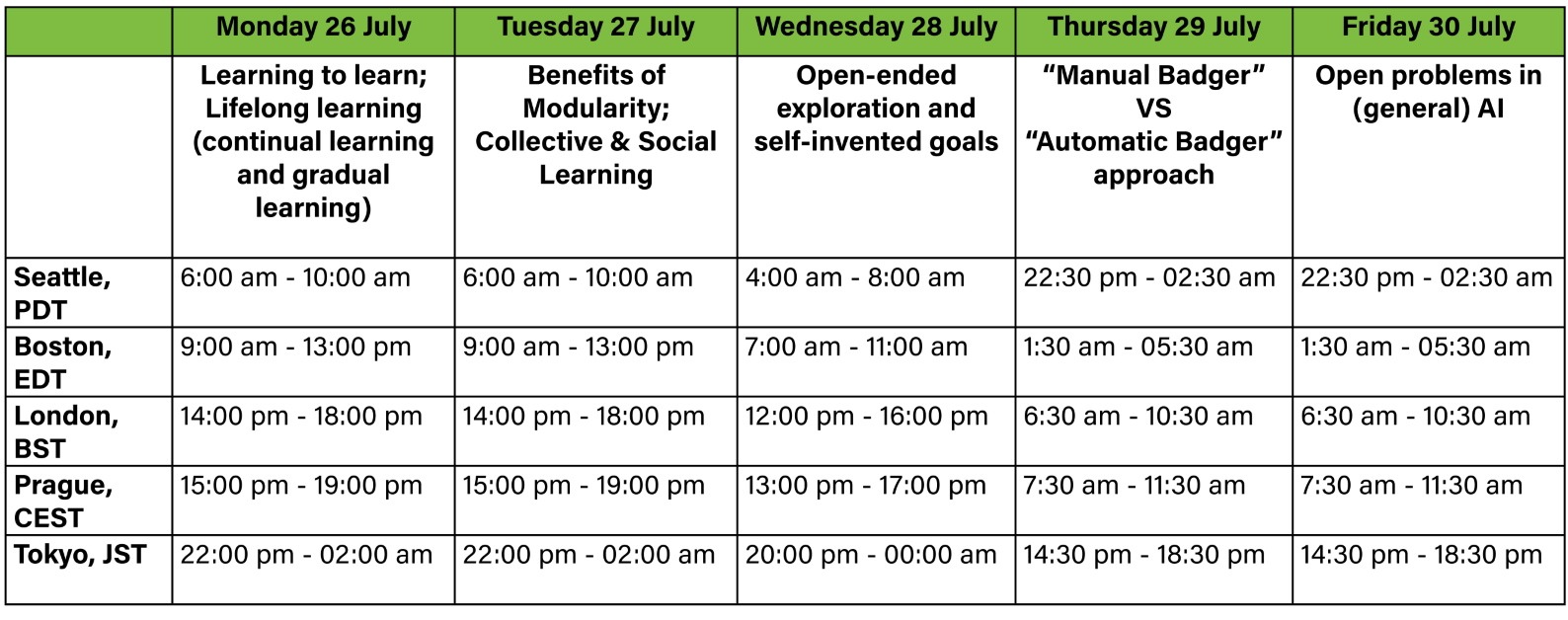
July 26 – 30, 2021
As previously, we held the seminar in a hybrid form: online and at the GoodAI headquarters in Prague – The Oranžérie.
Read the full summary here.
Schedule
Format
The seminar featured focused group discussions, and took an interdisciplinary approach drawing on the fields of: meta-learning, artificial life, network science, dynamical systems, complexity science, collective computation, social intelligence, creativity and communication, and more. The idea for this seminar came from the type of questions we’re solving while working on our Badger Architecture.
Code of conduct for the seminar
All attendees and speakers must abide by GoodAI’s Code of Conduct during the seminar.