The first of many rounds in the General AI Challenge series was running from February to August 2017.
What our finalists say:
I discovered the challenge just two months before the deadline. I was completely thrilled and jumped into it without a doubt and with renovated passion for almost 150 hours during weekends and daily spare time. It was absolutely amazing to find out that GoodAI was making a challenge out of my favorite programming topic and providing a framework for it as well! I believe that initiatives like these will definitely accelerate the research towards a general AI, bringing together ideas from all around the world, for the greater good of humankind. Ideas that had been dormant before and would otherwise remain silent.
The prize came as a bit of a surprise to me - my submission was not yet what I wanted it to be. Suffice to say, I feel extremely honored, amazed, grateful, thrilled, even nervous, and most definitely excited. And with renovated energy and passion to continue reaching one step further each month, each week, each day.
Andrés del Campo Novales
Software engineer, AI hobbyist
Developing a general AI from first principles is an interesting challenge that has already yielded some results that I can apply to the robots we use today. I'm excited to be one of the winners and am looking forward to learning about how others approached the problem.
Dan Barry
NASA astronaut, founder of Denbar Robotics
the challenge is a good opportunity for motivating people to work on general AI. It is a great pleasure for me to win a prize in the first historical round. On the other hand, I regret that my agent did not perform well enough for the quantitative prize. I will challenge again when I have a chance to win.
Susumu Katayama
AI researcher
Understanding the human brain is one of the big remaining quests we have, and it seems that machine learning takes us a big leap in this direction - still, despite all efforts, we have not reached the goal of general artificial intelligence yet.
This challenge gave me the opportunity to delve into the topic of artificial intelligence from a new perspective. I am very happy to receive the prize, and my AI agent is even happier about it (just kidding ;) )
Andreas Ipp
Quantum physicist
The first of many rounds in the General AI Challenge series was running from February to August 2017.
We used the term “warm-up” because the tasks in this round were relatively minimalistic, and the artificial environment used to design the tasks was constrained and noise-free. We tried to isolate the problem of gradual learning and let you play with it without distractions.
For the Gradual Learning round of the Challenge we received 13 submissions, including eight agents.
The agents were evaluated using a curriculum designed specifically to test their gradual learning capabilities.
None of the agents were able to solve the curriculum, so all of the submissions were evaluated by a panel of judges for the “best idea prize” – the submissions which demonstrated potential of scalable gradual learning.
See below for the results as well as full details of the evaluation process.
The Goal
The participants were programming and training an AI agent to engage in a dialogue with the CommAI-Env environment. They were expected to exchange bytes of information, and in addition the environment gave feedback signals to the agent to guide its behavior.
The agent should demonstrate gradual learning—the ability to use previously learned skills to more readily learn new skills (and in this case, to answer questions generated by the environment).
The participants were not optimizing the agent’s performance on existing skills (how good an agent is at delivering solutions for problems it knows). Instead, the goal was to optimize the agent’s efficiency at learning to solve new/unseen problems.
We provided the participants with a platform-independent (Win,Linux,Mac) set of training tasks that could be used as reference, implemented in CommAI-Env. The tasks are based on the CommAI-mini set recently proposed by Baroni et al., 2017 (https://arxiv.org/abs/1701.08954).
This video demonstrates three examples of the tasks that the agents needed to solve in the first round of the General AI Challenge.
The agents were evaluated on similar, but not identical evaluation tasks. This way we avoid the case that the agent has been built for the given tasks only. Instead, it should possess more general ability to learn how to learn.
To train and test their agents, the participants were given free access to Microsoft Azure cloud space, provided by our technological partner Microsoft Czech Republic and Slovakia.
The prizes
Participants competed for prizes in two categories:
Quantitative prize: for agent that solves all evaluation tasks within the smallest number of simulation steps using gradual learning. This one used objective evaluation / black-box testing (not subjective, no jury, no evaluation of designs, etc).
1st place : $15,000
2nd place: $10,000
3rd place: $5,000
Qualitative (aka “best idea”) prize: for the idea, concept, design that shows the most promise for scalable gradual learning. This one was subjective, jury, white-box evaluation.
1st place: $10,000
2nd place: $7,000
3rd place: $3,000
In addition to the monetary prize, the participants competed for a cutting-edge NVIDIA GPU!
Timeline
A look back at the Gradual Learning round:
Warm-up round launch: February 15, 2017
Evaluation start: August 15, 2017
Solution submissions were due by August 14th 2017, 23:59 CET (code and whitepaper describing the solution)
The participants could send as many solutions as they’d like, but each had to be significantly different from others
End of evaluation period: September 15, 2017
Announcement of results: September 30, 2017
Evaluation and results
The Gradual Learning round had two categories of prizes: quantitative and qualitative.
Quantitative prize
The quantitative prize was reserved for the AI agent that solved all of the evaluation tasks within the smallest number of simulation steps using gradual learning.
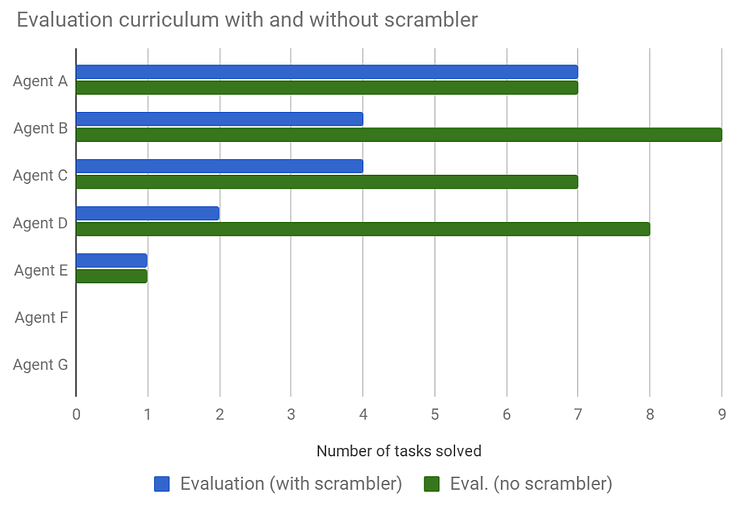
GoodAI team members tested the eight submitted agents using an evaluation curriculum. The evaluation curriculum was kept secret and was designed by modifying and extending the public curriculum. One of the changes, adding a scrambler, designed to encourage general solutions, also made the evaluation significantly more difficult. For comparison, the agents were tested on a curriculum with and without the scrambler applied.
None of the submitted agents were able to complete the evaluation curriculum. The most successful agent got close to completing 25% of the tasks (see the chart). Therefore, the quantitative prize was not awarded in this round.
Qualitative prize
The Qualitative prize is to be awarded for the idea, concept or design that shows the most promise for scalable gradual learning.
All 13 submissions were eligible for the qualitative prize. First, to avoid bias, part of our team analyzed the white papers, without looking at the agents’ performance. The GoodAI team shortlisted six of the submissions. Authors of four best scoring papers happened to submit agents, which also performed better than the rest in objective tests.
The shortlisted solutions were passed on to the final jury made up of:
Pavel Kordik (Czech Technical University)
Alison Lowndes (NVIDIA)
Tomas Mikolov (Facebook AI Research)
Roman Yampolskiy (University of Louisville)
Members of the GoodAI team
In addition to all the information that the participants made available in their solution, including their papers, the jury took into account the agents’ performance on the evaluation curriculum, and on additional tests for gradual learning (see summary of evaluation for details of the tests). Each member of the jury voted for three best solutions (by awarding points from 0 to 3).
Four solutions with the highest number of points emerged. The jury concluded that the presented solutions are closely comparable, and more work is required to demonstrate that the authors are on track to robust gradual learning mechanisms.
The jury selected no winner, but to encourage further work on gradual learning and to reward the participants for their considerable efforts, they decided to split the 2nd prize ($7000) among the four finalists.
The recipients of the joint award are (in alphabetical order):
Dan Barry
a former NASA astronaut and a veteran of three space flights, four spacewalks and two trips to the International Space Station. He retired from NASA in 2005 and started his own company, Denbar Robotics that focuses on smart robots and artificial intelligence interfaces, concentrating on assistive devices for people with disabilities. In 2011 he co-founded Fellow Robots, a company that provides robots for retail settings. He has ten patents, over 50 articles in scientific journals and has served on two scientific journal editorial boards.
Andrés del Campo Novales
AI hobbyist passionate about the idea of a general AI. He is a Software Engineer with 15 years of professional experience. He has been working for Microsoft in Denmark for the last 11 years in business applications. Andrés studied computer science & engineering at Córdoba and Málaga. He created a chatbot that could learn conversation patterns, context and numerical systems. Download white paper submission and code.
Andreas Ipp
research fellow at the TU Wien where he obtained his habilitation in the field of theoretical physics. His current research is focused on simulating the production of the quark-gluon plasma in heavy ion colliders like the LHC in CERN. After obtaining his PhD, he had postdoctoral fellow positions in Italy and at the Max Planck Institute in Germany. Since his return to TU Wien, he is involved in teaching activities, including lecturing on quantum electrodynamics. Apart from his scientific achievements, he founded the choir of the TU Wien a few years ago, which successfully participates at international choir competitions. Download white paper submission.
Susumu Katayama
assistant professor at the University of Miyazaki in Japan, inventor of the MagicHaskeller inductive functional programming system. He has been working on inductive functional programming (IFP) for fifteen years. His research goal is to realize a human-level AI based on IFP. Download white paper submission and code.
Although all the judges agreed that the solutions are closely comparable, and each of them have their own notable aspects, the solution by Andreas Ipp was the one that received most points. On top of the split monetary prize, the jury awards Andreas Ipp with the special GPU prize from our Challenge partner NVIDIA – a GEFORCE GTX 1080 graphics card.
The following are several takeaways from the first round which we intend to use as inputs for improving the future round(s):
Since nobody was able to solve the Gradual Learning round, we are going to again dedicate one of the upcoming rounds of the General AI Challenge to solving gradual learning.
We want to keep the participants excited and motivated during the whole run of the Challenge round. We are considering a leaderboard with automated evaluation for this purpose.
Iterative evaluation: some submissions took the whole 24 hours of the evaluation CPU time for trying to solve the first task. This was essentially a waste of resources. We are considering including stages in the challenge evaluation so that only agents that reach a threshold task within the given time limit will be allowed to run for the full 24 hours.
Simplified interface: we found out that the 256-value UTF-8 interface caused too many (unnecessary) technical difficulties for the participants. We will therefore limit the data on the interface to printable ASCII characters only.
More time for solving a task instance: some of the earlier tasks switched the instances earlier than participants of the challenge would like. Since learning from limited data was not the point of the challenge (although faster learners are preferred by the evaluation), we’ll let the instances run for longer.
We are considering performing another round of human performance tests, this time with scrambler to remove many of the human biases from the tasks.
In future rounds of the Challenge that will involve programming, in order to be as objective and transparent as possible, we will go with quantitative evaluation only (objective tests). Evaluating for the qualitative (aka “best idea”) prize was a great experience for us and the wider jury, but at the same time, to judge technical proposals based on relatively limited information available proved to be more challenging than we expected.
Next Steps and Future Rounds
In 2018, we plan to launch another round of the General AI Challenge focused on gradual learning. For this reason, we are publishing only those tasks from the evaluation curriculum, that the AI agents were able to solve in Round 1 (see Evaluation Results document). The rest of the tasks will stay secret and will be reused in the upcoming gradual learning round – part II.
In the meantime, in November 2017, we will launch Round 2 of the Challenge: AI Race Avoidance. Since the goal of the Challenge is to help solve all pieces of the puzzle that will lead to beneficial future with general AI, we are interested in societal implications of AI as much as in technical milestones.
We invite you to keep following the General AI Challenge and participate in future rounds!
Get involved!
Be a part of shaping the General AI Challenge and its goals. The Challenge is open to both individuals and teams.