Authors: GoodAI Team, and a special thank you to grant recipients for their contributions and comments.
Summary
- In 2021/22 GoodAI will focus on four core research areas: learning to learn, lifelong (gradual) learning, open-endedness, and generalization / extrapolation of meta-learned algorithms.
- These areas are being investigated by the GoodAI core R&D team as well as grant recipients who have received funding through GoodAI Grants, to conduct research aligned with topics relevant to GoodAI’s Badger architecture principles.
- This document outlines the requirements for the system GoodAI is developing and for the environment in which the system will be trained and tested, and paths towards implementation.
- An exciting R&D year lies ahead of us and we continue to seek collaborators, especially in the topics we will now focus on.
The goal of GoodAI’s Badger architecture [1] and the desired outcome of our research is the creation of a lifelong learning system (e.g. an agent) that is able to gradually accumulate knowledge, effectively re-use such knowledge for the learning of new skills, in order to be able to continually adapt, invent its own goals, and learn to achieve a growing, open-ended range of new and unseen goals in environments of increasing complexity. We envisage that the creation of such a system is possible through careful meta-learning of a distributed modular learning system together with developing and deploying the appropriate minimum viable environment/dataset, cultivating the necessary inductive biases to afford the discovery of a lifelong learner with such properties. The following roadmap is a description of the next steps that we are taking in order to achieve this goal.
How this relates to GoodAI’s overall mission:
The goal of GoodAI is to build safe general AI – as fast as possible – to help humanity and understand the universe. Our long-term vision is to augment human capabilities with “scientist AIs” and “engineer AIs”, to be able to address humanity’s most dire problems that otherwise would have taken many human generations to solve (one can argue, we can’t afford ourselves infinite time). In our understanding, the lifelong learning system with properties we describe further down is the cornerstone of general AI.
Why are we publishing this?
The purpose of this article is to introduce, to a wider audience, GoodAI’s broader research plan for 2021/2022. We believe that openness and transparency allows for informedness that fosters collaboration and eventually a community, an endeavour that we consider to be necessary for building agents with all the desired capabilities we would like them to have. To that end, we:
- Describe how GoodAI’s research, projects supported through GoodAI Grants, and other related work in our view fit together in a bigger picture,
- Hope to entice discussion and collaboration by suggesting connections and interdependencies between individual research ideas and their realizations,
- Forewarn that the research agenda can be dynamic and subject to adjustments as we progress and learn more.
Desiderata
First, we would like to outline some of the requirements for the systems we are building. This serves as one of a number of guiding foundations for planning and determining the next steps in our research. For clarity of exposition, we will refer to the system we are building as an agent, even though most of the discussion is applicable to simpler as well as more complex embodiments, from classifiers to multi-agent systems as well as many other machine learning / artificial intelligence models and methods.
Agent Desiderata
The desired properties of the agent we are building are plentiful and each a substantial research challenge on its own, before even considering the learning of such properties automatically:
- Learning to learn [2]–[8].
- Lifelong learning (continual, gradual) [9]–[13].
- Gradual accumulation of knowledge and skills
- Reuse of learned knowledge and skills for subsequent skill discovery and learning (with forward & backward transfer [10])
- Open-ended exploration [14], [15] and self-invented goals [16]–[20].
- Out-of-distribution generalization [21]–[24] and extrapolation to new problems [25], [26].
There are many approaches to building agents with these properties. At GoodAI we’ve converged on key principles (modularity of the agent, shared policy of the modules with different internal states, meta-learning in the outer loop followed by open-ended learning in the inner loop) which we employ in our Badger architectures, and which we will describe in the section “Towards Implementation”. Here, it is important to note that the agent should possess these properties at test time, i.e. in the inner loop (agent’s lifetime), if we are considering an agent trained via meta-learning (a bi-level optimization process where optimization occurs on two-levels [4], [27], [28]), a setting which should be considered the default one throughout this article, unless stated otherwise.
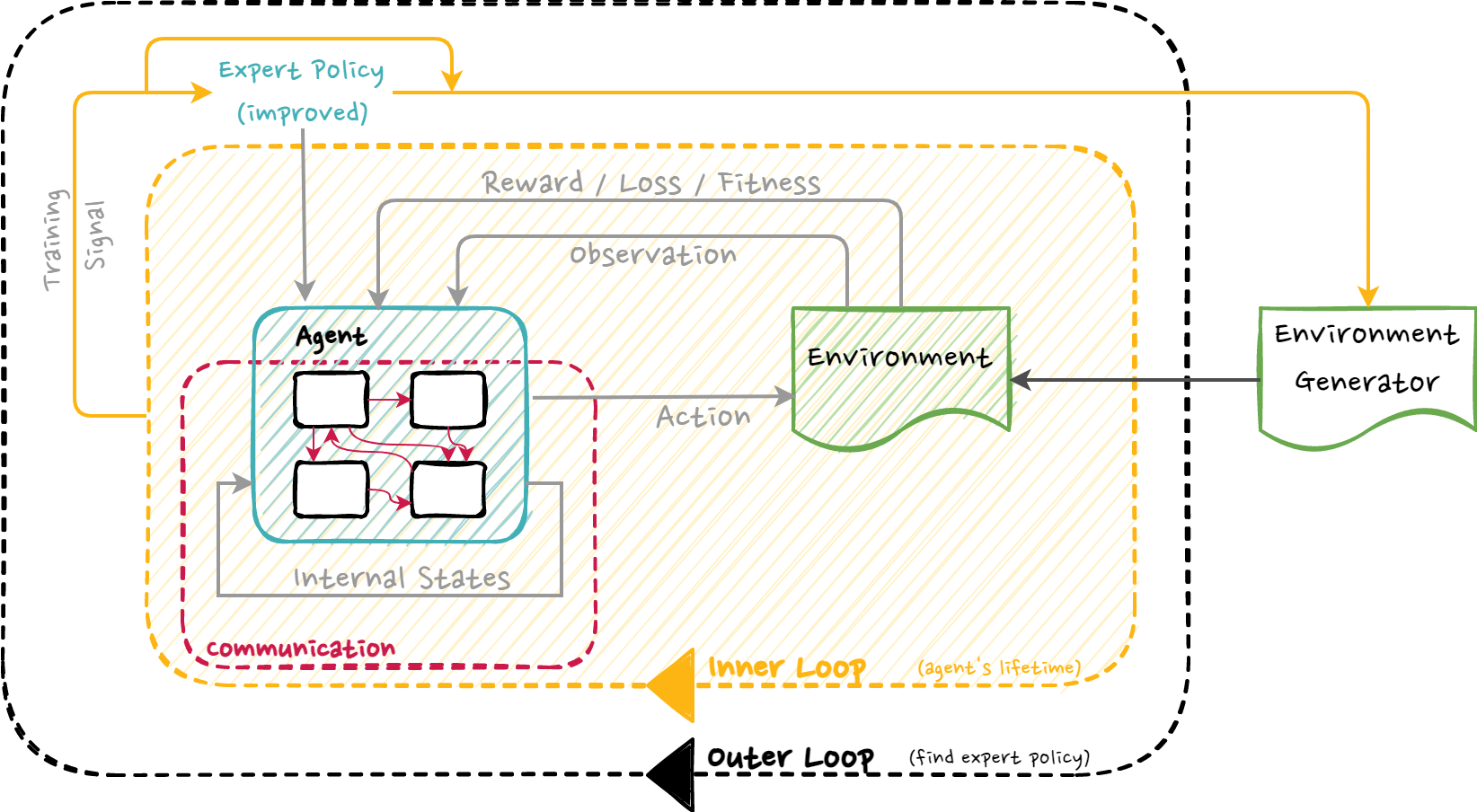
A Badger agent can be trained using bi-level optimization in which two learning loops exist, an outer loop and an inner loop. During outer loop training, the lifelong learning capability (along with the other requirements outlined in an earlier section) of the agent is learned, whereas during the inner loop, the agent will be subjected to vast curricula on which it will be continually trained to build a repertoire of abilities that should be converging towards a human-level skillset.
Below, we suggest how to approach the evaluation for requirements that should be present during the agent’s lifetime (inner loop):
- Lifelong learning [9]–[13] – an agent demonstrates efficient and effective sequential learning, and in turn retains knowledge it has learned from different tasks (avoids catastrophic forgetting [10]) with reuse of previous knowledge when learning to solve new tasks, i.e. selective transfer of knowledge to facilitate learning of new tasks.
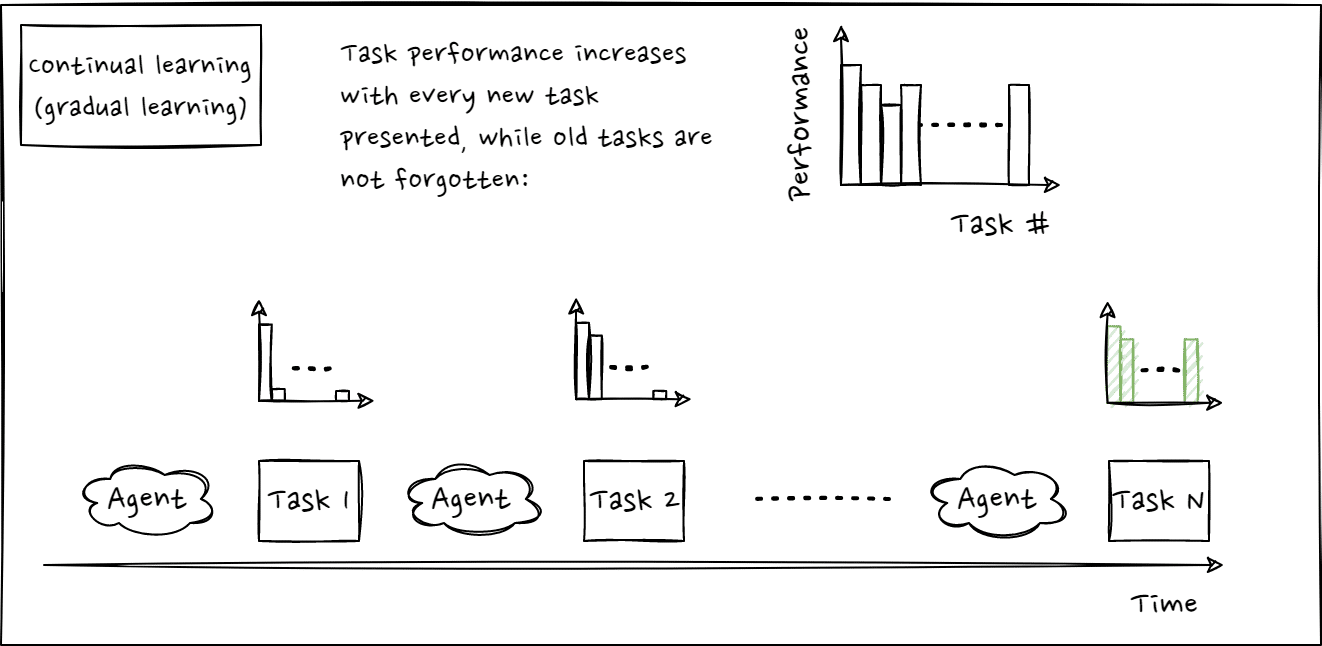
- Performance on novel tasks should steadily improve over (inner loop) training time thanks to lifelong learning capabilities. Any recent fine-tuned ImageNet image classifier architecture paired with gradient descent might show such steady progress [29], [30] albeit only on image classification tasks or data converted to images. Badger architecture should generalize to other kinds of tasks and domains too:
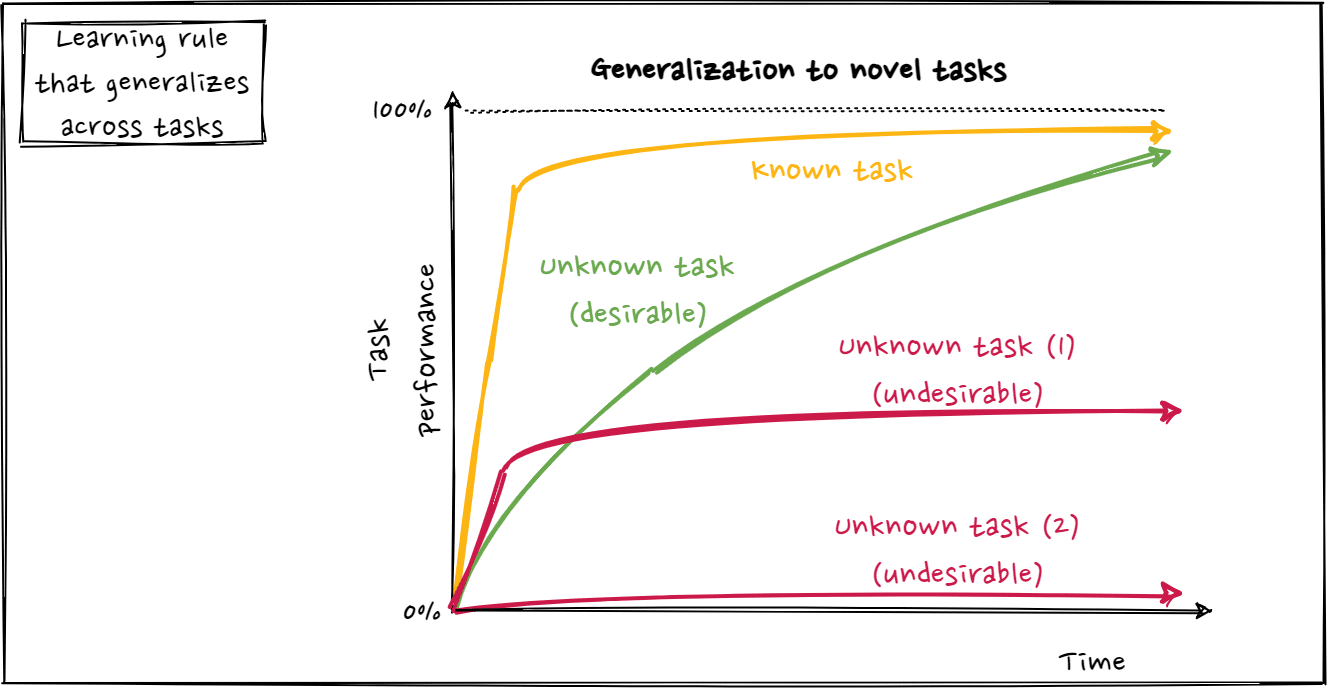
- Ability to generalize and extrapolate to out-of-distribution tasks during an agent’s lifetime (inner loop). In other words, the agent is able to learn, on its own, to solve more and more unseen tasks after being trained on an increasing number of tasks. Suitable datasets or environments in the outer loop improve generalization to unseen tasks in the inner loop:
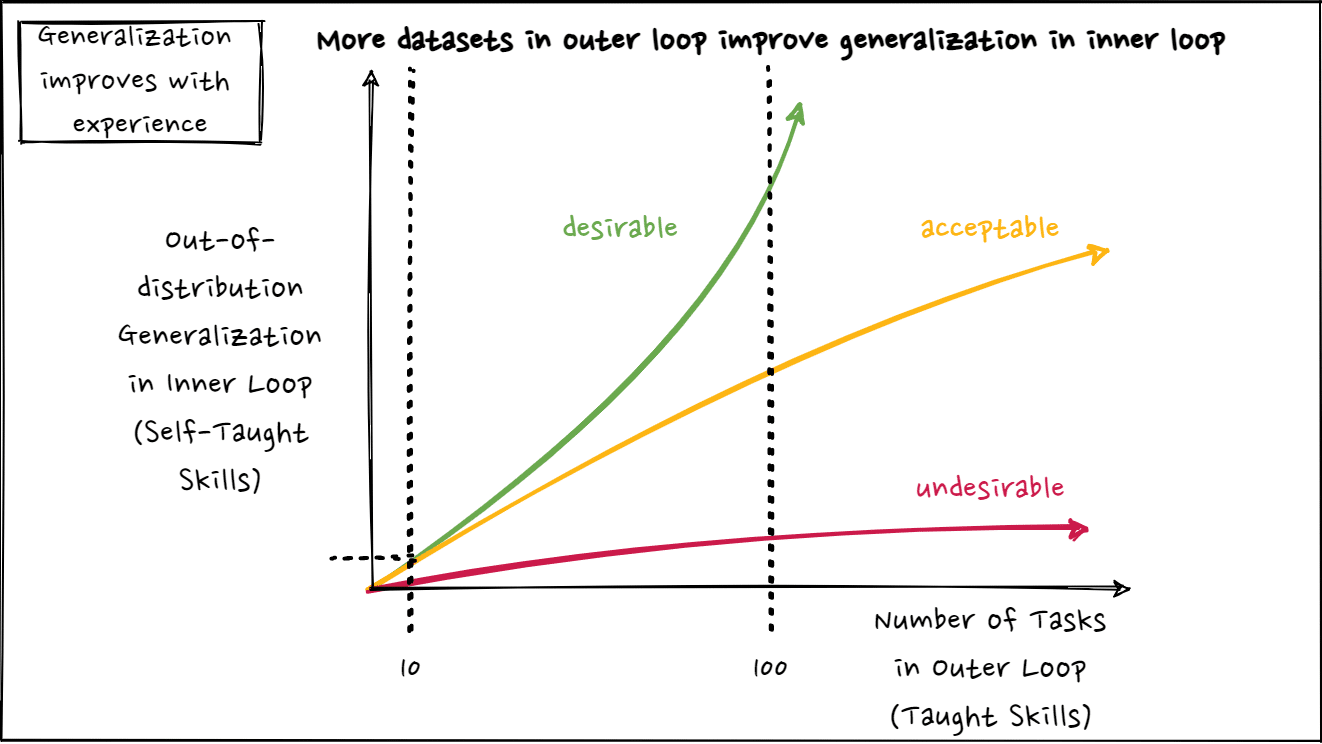
Outer loop datasets/environments don’t focus on task-specific knowledge, but on more abstract learning abilities that lead to lifelong learning. We believe that in order for the agent to be useful, lifelong learning in the inner loop should be performed on increasingly human-like gradual curricula. Performance on known tasks does not degrade dramatically as the system learns to solve new tasks.
Environment Requirements
Since our goal is a lifelong learning agent, the need for open-ended environments [15], [31] that will support this kind of learning is unquestionable. We believe productive learning environments should include:
- Distinct tasks with progressing complexity (enabling creation of sequential curricula) [32], [33].
- Interactivity – the agent’s actions affect the environment and have a lasting effect on it.
- Unbounded potential for complexity growth. Combination of building blocks can be the basis of further combinations, ad infinitum.
Recall that a Badger agent can be trained using bi-level optimization in which two learning loops exist, an outer loop and an inner loop. During outer loop training, the lifelong learning capability (along with the other requirements outlined in an earlier section) of the agent is learned, whereas, during the inner loop, the agent will be subjected to vast curricula on which it will be continually trained to build a repertoire of abilities that should be converging towards a human-level skillset.
We aim for the extensive reuse of skills in the inner loop. It is helpful to make a distinction between two types of skill reuse. Skills can be:
- Compositional (e.g. feature kernels of CNNs), a prerequisite skill that is a necessary part of other skills (e.g. last layer of a classifier network). The other skills will break if the prerequisite skill is removed. The other skills are functionally dependent on the prerequisite skill, once created.
- Transformational, (e.g. tool-like skills, such as reading) a means of obtaining other skills via learning. A transformational skill can be removed and the other skills it helped obtain still stay intact. The other skills are not functionally dependent on the transformational skill, once created.
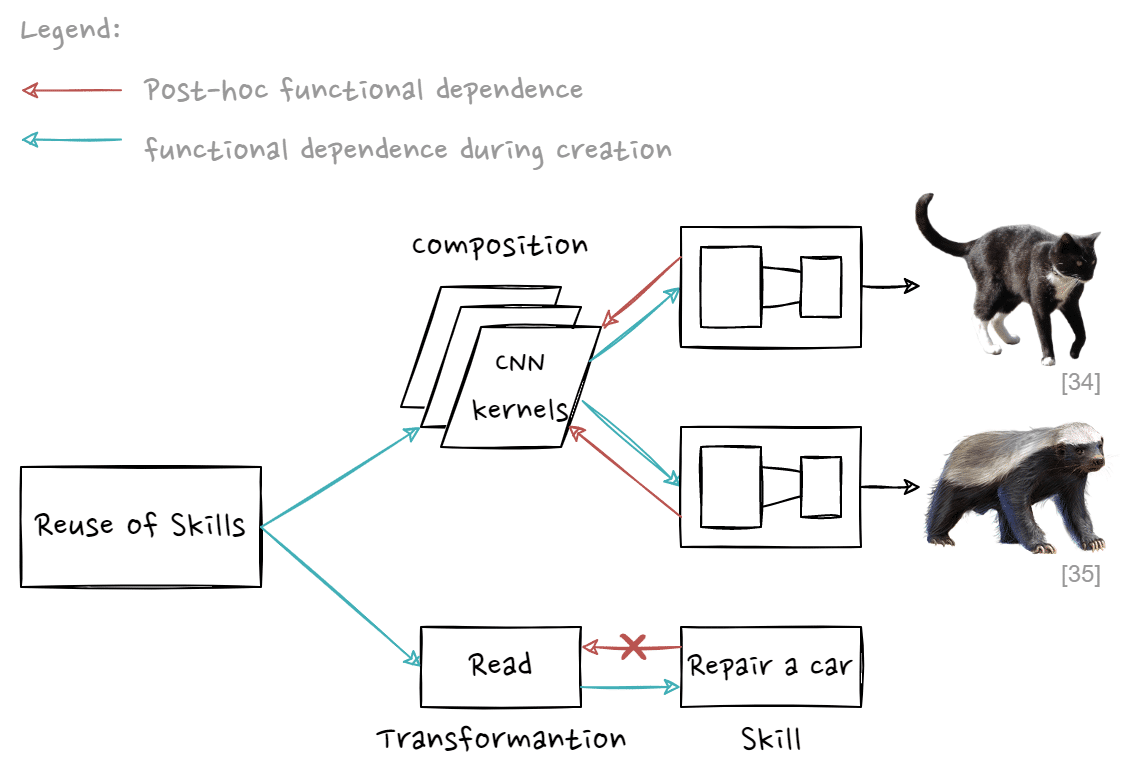
The environments/tasks that we use for evaluating the learning rule need to be aware of this distinction and capture both scenarios. Nascent reuse of skills can be thought of as a form of basic self-improvement in an agent, a property very important for Badger.
Towards Implementation
This section puts the GoodAI team’s Badger architectures, the work of the GoodAI Grants recipients, and other relevant research into the context of shared Badger principles.
Our goal is to create conditions for teams and individuals to collaborate across boundaries towards a bigger mission of general AI, cross-informing and complementing each other with research questions and findings. To date, most of what we consider general AI research is done in academia or inside big corporations. We believe that humanity’s ultimate frontier, the creation of general AI, calls for a novel research paradigm, to fit a mission-driven moonshot endeavor. The GoodAI Grants program is part of our effort to combine the best of both cultures, academic rigor and fast-paced innovation. Our goal is to accelerate the progress towards general AI in a safe manner by putting emphasis on community-driven research, which in the future might play a key role in preventing the monopolization of AI technology and ensuring that humanity as a whole can benefit from it (see AI race [36]).
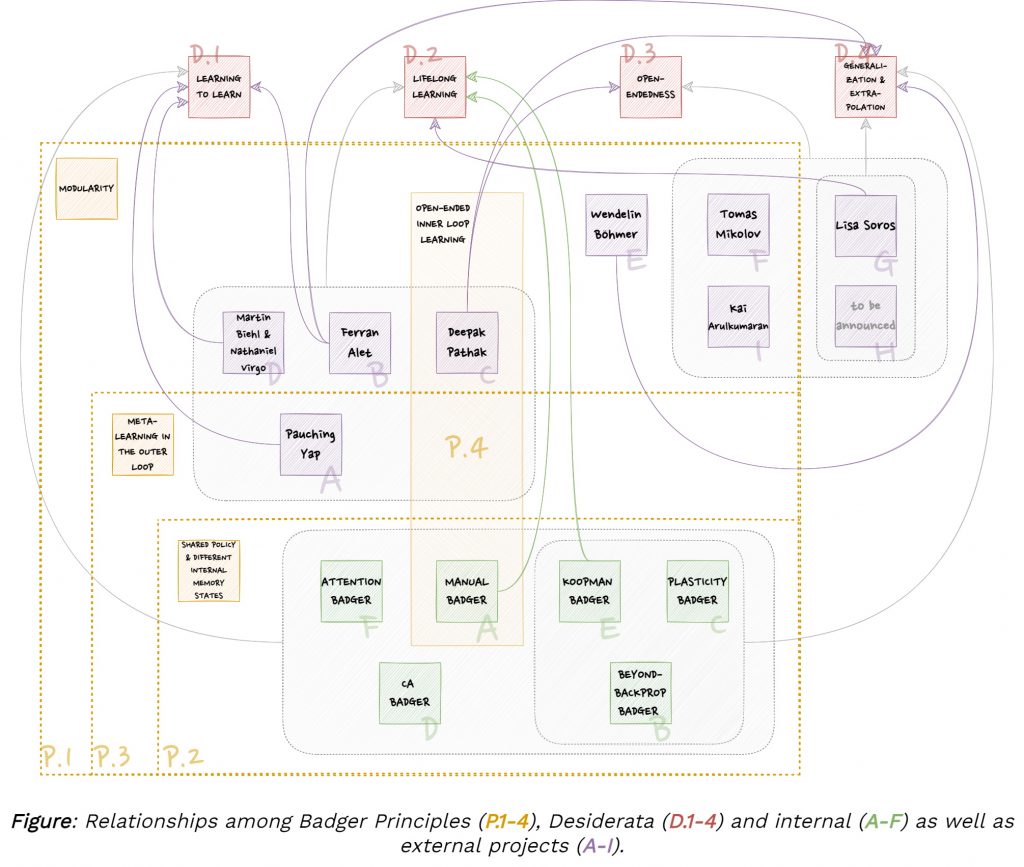
Shared Badger Principles
GoodAI is developing several branches of Badger architecture. The core Badger principles are shared across these architecture variants, and with a number of external projects outlined in the next section:
- Modularity and Compositionality (agent composed of individual modules)
- Modules/experts share a (single/few) policy, but each has a different internal state
- Meta-learning phase (outer loop) leads to learning a learning process that is executed in the inner loop
- Open-ended inner loop learning as a means to lifelong learning
*note that we use the terms “modules” and “experts” here interchangeably. The term “expert” isn’t referring to an “expert system” but to a module capable of adaptation through the change of its internal state.
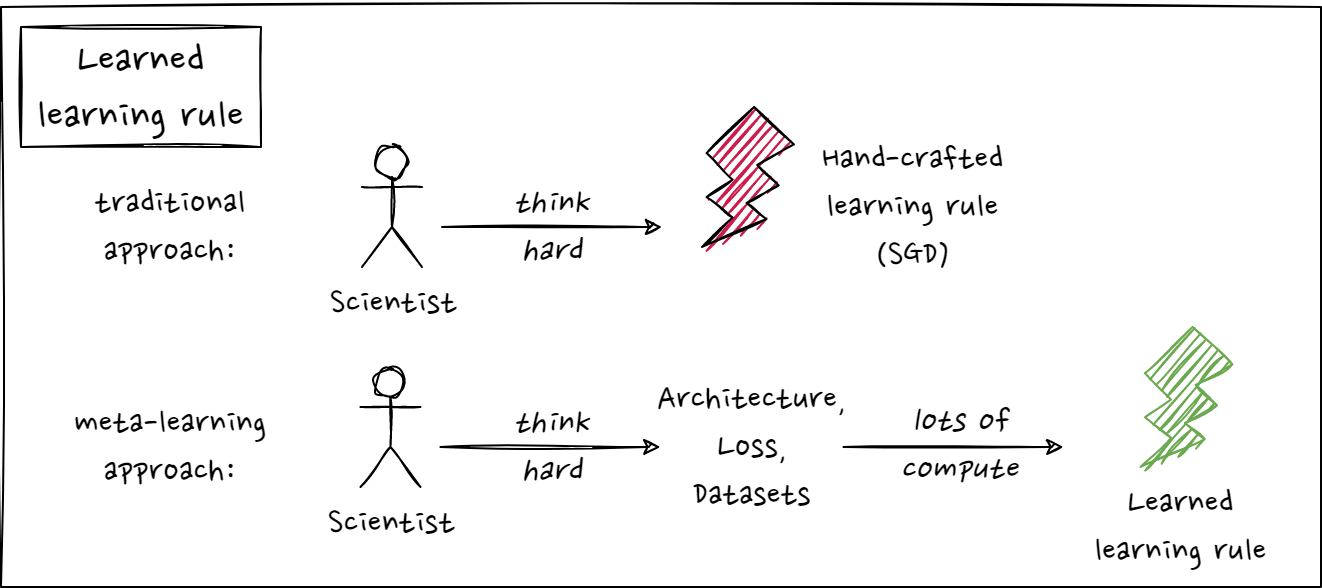
Generality of Badger
It is important to note that despite the fact that we primarily describe Badger as an agent that is able to perform sequential decision-making, Badger is a system that is applicable across scales, from the neuronal level, all the way to the collective decision-making of nations, states and other large entities.
Mapping of Badger Principles to Desiderata
Desideratum #1: Learning to Learn
Learning to learn is notoriously difficult. There have been many attempts to design an adaptive, improving learning algorithm, but none to the level of quality and generality that would go beyond hand-engineered methods. Inspired by the success of automatically learned visual features in NN classifiers [37], GoodAI strives to find the adaptive, self-improving learning algorithm through automated search. We are building a meta-learning setup (Badger principle 3) that uses existing hand-engineered learning algorithms, such as gradient descent with backpropagation, to find a universal learning rule/algorithm (outer loop), that is able to run over many (possibly infinite) iterations over a task or a sequence of tasks (inner loop). The policy shared between modules/experts (Badger principle 2) that together compose the modular Badger architecture (Badger principle 1) is key for the effort – not only does it bring down the number of parameters that need to be optimized in order for the learning algorithm to be discovered, but more generally allows for the representation of types of learning that go beyond the standard optimization view [38], [39].
This setup enables us to focus on the formulation of the desirable features of the adaptive learning algorithm, while opening itself to optimization and beyond as well as the possibility for data-driven improvements. Finding the adaptive learning algorithm has been the key objective of our numerous implementations, including Attention Badger, Koopman Badger, Cellular Automata (CA) Badger, Plasticity Rule Badger or Beyond-Backprop (B2) Badger, all discussed in further detail below.
Link with awarded GoodAI Grants:
Ferran Alet’s compositional learning algorithm is an example of a learning algorithm that is adaptive to a combinatorial range of tasks thanks to a design that leverages modularity. Additionally, his project aims to discover a self-improving learning algorithm.
Pauching Yap investigates how an existing continual learning framework called Bayesian Online Meta-Learning [40], based on Model-Agnostic Meta-Learning [41], can be extended into a modular setting and utilized in novel learning scenarios.
Martin Biehl and Nathaniel Virgo investigate how by studying different goal structures, including those of multi-objective setups, one might expect to be able to extract principles that make problems suitable for multi-agent/modular approaches, in particular in learning to learn/meta-learning contexts.
Desideratum #2: Lifelong learning
We understand that the path towards general artificial intelligence cannot lead through learning from independent and identically distributed data only. Hence our focus on sequential learning – data presented in a distribution that evolves and changes significantly over time. We intend to build the life-long learner out of an inner loop that is allowed to run longer and longer, eventually reaching a state when stopping it is no longer required and it runs in an open-ended manner (Badger principle 4).
Manual Badger is directly focusing on lifelong learning via an infinite/continual process, without an outer loop, within which learning emerges through collective computation. Beyond-Backprop Badger investigates how a meta-learned update rule can be adapted once executing in the inner loop, targeting lifelong learning capabilities without subsequent outer loop procedures. Koopman Badger attempts to exploit the infinite time properties of the Koopman operator to design continual optimizers able to learn to solve more and more tasks.
Link with awarded GoodAI Grants:
Deepak Pathak’s long-term research goal is enabling life-long learning in deep learning systems. In connection to the grant, Deepak will study the application of a message-passing multi-agent framework for continual learning for computer vision. Moreover, his research into generalizing algorithms works as an enabler for continual learning.
Ferran Alet’s compositional learner features self-improvement as an eventual goal – a learner that improves itself on the fly, the more tasks it sees.
Pauching Yap is working on building a sequential Bayesian learner with incorporated Badger principles, especially modularity and meta-learning.
Martin Biehl and Nathaniel Virgo are working on a project that attempts to provide mathematical tools for analysis and understanding of multi-agent learning, achieving multiple goals and dynamic scaling of multi-agent systems.
Desideratum #3: Open-endedness and self-invented goals
The life-long learning desideratum implies the need for open-endedness and self-invented goals. Any training curriculum made up of a predefined set of tasks will eventually run out either of tasks or of tasks that have a meaningful difficulty for the learner.
The real world is an example of an environment where intelligent agents (humans) have always managed to set goals and provide tasks with complexity that would match the capabilities of the learner present in that environment. The downside of the real world is the cost of experimentation of course – we are looking for an artificial environment that retains the open-ended task emergence properties of the real world, while allowing us to bring the computational requirements down by orders of magnitude. The learner that operates in such an environment should not be limited in the number of tasks it can invent or solve. Its learning should therefore run in an open-ended manner (Badger principle 4), open to self-improvement and adaptation.
Manual Badger investigates how skills can be discovered and invented without any external supervision and in an open-ended manner, while Plasticity Badger investigates the surprising possibilities that random environments afford to learned learning algorithms.
Link with awarded GoodAI Grants:
Lisa Soros is doing research focused on the design of the environment and trying to guarantee the presence of open-endedness while maintaining the simulation complexity at reasonable levels and avoiding hand-designed rewards or feedback.
Tomas Mikolov is aiming to simplify novelty search and curiosity-driven exploration in order to enable faster exploration and discovery of interesting environment features.
Deepak Pathak is working towards a general-purpose unsupervised algorithm that allows the agent to explore and then learn to achieve the goals discovered via exploration. This equips the agent with the ability to achieve arbitrary diverse user-specified goals at test time without any form of supervision.
Kai Arulkumaran focuses on open-endedness (through multi-agent interaction) in computational creativity. Furthermore, he aims to investigate the role of non-pairwise agent interactions and meta-learning, which are underexplored in open-endedness research.
Desideratum #4: Out-of-distribution generalization and extrapolation to new problems
Humans are very good at generalization and extrapolation: we are able to quickly solve previously unseen tasks by piecing together new strategies from previous experience. This desideratum is backed strongly by the modularity and compositionality principle (Badger principle 1). The ability of the learned learning rule to generalize to unseen tasks is a key feature tested on architectures developed internally (e.g. Plasticity Badger or Beyond-Backprop Badger). We seek to learn learning algorithms that extrapolate to tasks unseen during training and that allow for the learning of “virtual” models. These models would live in Badger expert’s’ activations and generalize to at least the same levels as state-of-the art ML models.
Link with awarded GoodAI Grants:
Ferran Alet’s project proposes an algorithm that features out-of-distribution generalization by composing known concepts in novel ways and is able to search this exponentially-large solution space in polynomial time.
Going to a meta-level, Deepak Pathak is investigating modular message passing as a general approach to continually adapt at test time.
The work of Lisa Soros also helps bring a diversity of tasks that provide the learning system with just the right training data for getting better at solving new problems.
Index of GoodAI’s Ongoing Work
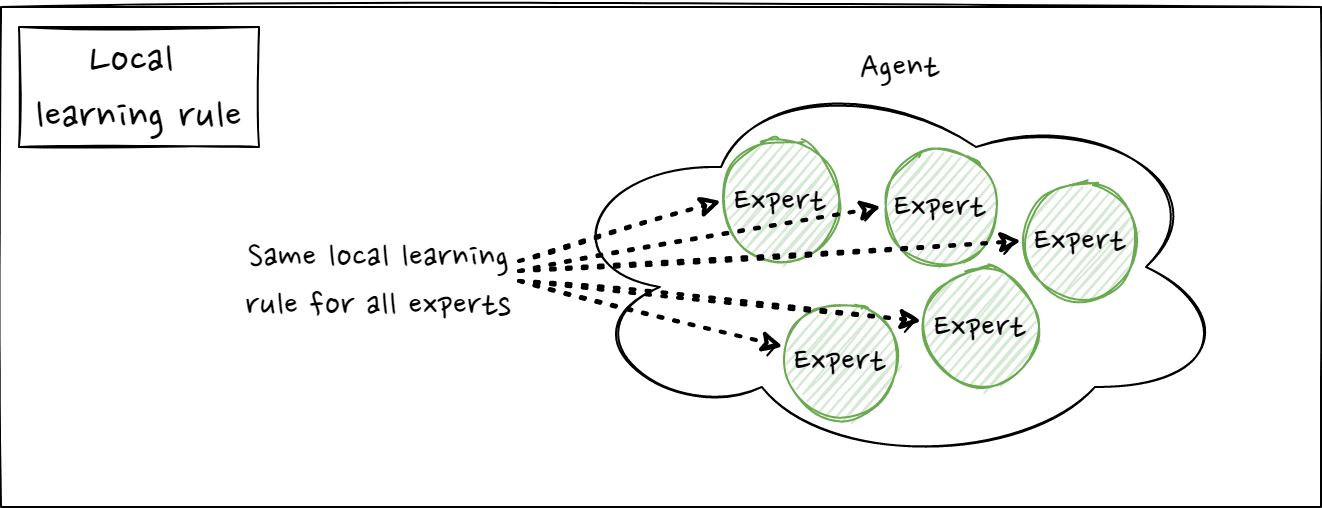
There are two high-level approaches to Badger research. An “automatic” approach and a “manual” approach. As the names suggest, the primary difference between the two approaches is the level of automation within the research and development process of a Badger agent. One of the core principles of Badger in general is the discovery of an expert policy or policies that governs the life-time behaviour of a Badger agent. In “Automatic Badger”, this policy is homogeneous, i.e. the same across all experts (modules), or it is a number of policies, most likely fewer than the number of experts. These are discovered via a bi-level optimization process, e.g. meta-learning. The “Manual Badger” path, on the other hand, takes a population approach with as many policies as experts that, over time, might homogenize to a smaller set of policies. The policies discovered here are through a combination of hand-engineered and learning mechanisms that allow for the easy incorporation of many inductive biases, rather than entirely through meta-learning. What both approaches share is that experts can be parametrized through an internal state, i.e. each expert has a policy and some data.
Manual Badger
The Manual Badger approach stemmed from the desire to investigate the limits and possibilities of building complex decision-making systems from a population of small processing units with relatively simple and predefined behaviours. In other words, how far can we get by using a collection of agents/experts with a hand-coded, pre-designed policy? How does such a collective system evolve over time and what are eventually its long/infinite-time emergent behaviours and capabilities?
As no outer loop learning process is used here, Manual Badger directly targets the life-time behaviour (eternal loop) of the agent during development. This is contrasted with Automatic Badger and shown in the following figure:
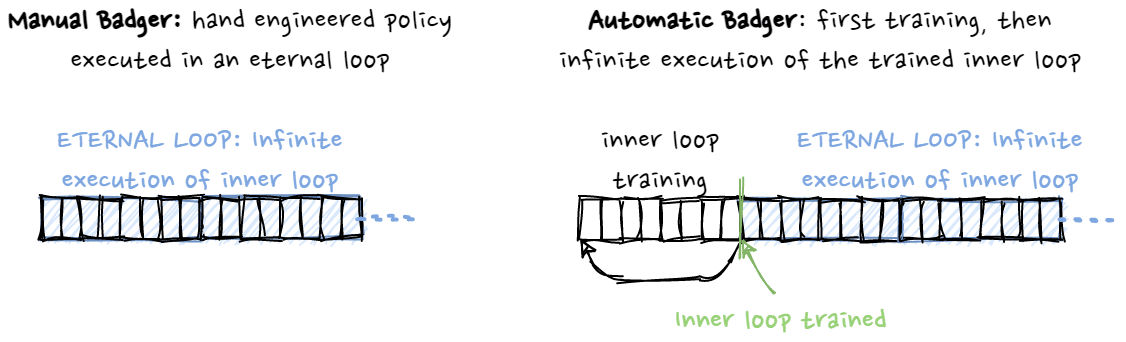
A. Memetic Badger
The present connectivity and update step is analogous to cellular automata: experts reading output messages of their close neighbors and outputting their own outputs for the next step.
This system has no hardcoded fitness function. There’s only endogenous and evolvable fitness: those who can spread will propagate their values.
This setup is analogous to coevolution of memes and genes in a society (genes are the experts in our case). Memes are influencing the genes, and genes are influencing the memes, opening doors for Baldwin effect dynamics.
We expect that the coevolution between the population of expert policies and memes will drive the emergence of more complex expert policies and more complex memes. Memes that are better at spreading and better at discovering new niches should gain an advantage.
Behavior of memes will create new resources for other memes, leading to evolution in divergent ways. Memes control how memes spread, replicate, and how new memes emerge. Memes compete for resources (for experts, for exploitation of other memes). They also cooperate, for example by forming aggregates.
We expect that the eternal inner loop will lead to evolution of memes that are efficient at spreading, collaborating and/or exploiting other memes, at adapting to new challenges, and at evolvability.
The next stage will then be to direct this system to practical tasks.
A sample of our recent work in this area can be seen in [42].
Automatic Badger
Automatic Badger focuses on meta-learning an inner loop learning process, the expert policy, that will be able to automatically learn all of the desired properties of the agent. There are still many unknowns on how to achieve this goal most effectively and successfully and to what degree the properties of the agent are learnable vs. need to be encoded in the agent’s architecture as inductive biases or incorporated as part of the learning protocol. Such questions are actively investigated in a number of internal projects described below. Our initial guiding principles for the outer loop loss function design are the learnability of novel tasks as fast as possible, as well as the invention of the agent’s own goals, and the open-ended and non-diverging nature of the inner loop learning process.
B. Beyond-Backprop (B2) Badger
We can identify several classes of algorithms that aim to learn update rules in neural networks in a modular fashion.
- Algorithms belonging to the Learning-to-Optimize (L2O) family [43], [44] parametrize only the optimizer update step (while relying on autograd-like mechanisms to do the rest). Here, the learned optimizer receives at least the gradient and proposes a change to the corresponding parameters (independently per-parameter).
- Algorithms like BioSSL [45] are more general and parametrize not only the optimizer step, but also the credit assignment mechanism (backward pass). These typically expect terminal gradients on the input. Despite that, they do not rely on autograd anymore, the network structure is often chosen in a way that supports meta-learning algorithms similar to backpropagation (there is a clear distinction between the forward, the backward and the update steps).
- The last class is the most general one. Here, the forward, the backward, and the update mechanisms are all learnable, and there is no clear distinction between them. These algorithms are designed to be able to learn backpropagation, but theoretically can support learning algorithms that are very different from it [46], [47].
B2 Badger focuses on the last class described above. One interesting example of work, recently published by Louis Kirsch, is called Variable Shared Meta Learning (VSML) [46], which has a lot in common with Badger. In this work, the architecture is implemented as a network of interconnected LSTM networks that share the weights and communicate with each other. Each network has two input types: data input and feedback input and produces forward and backward messages. Meta-learning changes weights of these LSTMs, while during the inner-loop learning, only the LSTM activations change. As an inspiration for future work, we’ve been looking into the area of learned update rules, as well as the empirical properties of the VSML algorithm and its limitations.
Current progress on B2 Badger includes the exploration and search for the core properties that allow fully parameterized learning systems of the most general class of learned update rules (3) to function successfully. A minimum viable agent with such functionality is currently in development.
Future work will focus on some of the most promising directions:
- Creating a minimal model focused on meta-learning more general algorithms (e.g. reinforcement learning algorithms)
- Larger-scale meta-learning and more reliable convergence
- Finding out limitations which cause the meta-learned models to under-fit the data
- Improvement of out-of-distribution generalization properties
C. Plasticity Badger
Learned plasticity or learned update rules are an essential part of Badger architecture. In order to have a learned learning process in the inner loop, we need to venture beyond simple function mapping and focus on sequential dynamical processes that could result in learning algorithms that are able to learn in a continual lifelong manner. A good starting point for this investigation is the growing body of work on learned update rules, some of which draw inspiration from biology. In early 2021 we replicated and investigated results from Gu and colleagues [45]. We believe such approaches are an exciting stepping stone towards having continual learning capabilities in the inner loop especially in situations where unlabelled data is prevalent.
Using this model class as a base, we are further investigating avenues that are relevant to our work on Badger, namely:
- How to evaluate the efficacy of meta-learning methods in a standardized way.
- The role of update rules in the lifetime of training and how many discrete rules are useful for training, and how a meta-learner could discover this.
- How we can expand the distribution of tasks that the optimisation rule can be usefully applied to, without needing to expand the training set of the optimisation rule with such tasks.
D. Cellular Automata Badger
A Badger agent consists of multiple communicating experts (modules) with a shared policy. When experts are connected on a 2D grid and only local communication is allowed, the agent can be seen as a Cellular Automaton (CA).
Recent work on differentiable self-organizing systems [48] and neural cellular automata [49] have shown interesting capabilities of such systems – emergence of robust global behaviour by learning just local rules.
CA Badger explores badger principles on a CA model and uses “modules” – learned hidden state initializations that encode a policy. Such modules can then be combined to solve a specific task – e.g. copy a pattern, learn mapping of patterns, coordination.
Current progress:
- Scalability in # of experts
- Learned communication
- Learned common language in a mapping task between different alphabets
Next steps:
- Learn universal expert weights that will be interpreting a policy encoded just in modules (initialization)
E. Koopman Badger
Koopman Badger is a “Learning to optimize – L2O” approach that attempts to expand the original learning to optimize methods [43], [44]. Traditional L2O suffers from limited generalizability as well as a short-horizon bias which strongly limits its usage.
With Koopman Badger, we investigate applications and behavior of the Koopman operator [50], [51], which is a traditional method with only very recent applications in deep learning, see e.g.[52]. The Koopman operator is used to “rewrite” a non-linear dynamical system as a linear but infinite-dimensional dynamical system. This transformation allows us to inspect and predict the dynamics of the system using Koopman decomposition or Dynamic Mode Decomposition [53].
We describe the optimization process as a dynamical process. We extract eigenvalues and eigenfunctions of the dynamical system and use them as features for the learned optimizer.
Current progress:
- The optimizer uses information from the Koopman eigenvalues to gain aggregative information about the overall dynamics of all experts (modules)
- The learned optimizer generalizes significantly better even to novel tasks
- The optimization horizon is greatly increased compared to the original L2O method
Next steps:
- Explore ways to allow even longer horizons via regularization
- A gradually/continually learning optimizer
F. Attention Badger
In Attention Badger, an agent consists of multiple modules communicating through self-attention [54]. Each module is learnt to produce at most three vectors: key, query and value. The attention is computed multiple times to converge to the final result.
A module can be of three types:
- Input – only key and value are produced. Part of the environment is put on it’s input – e.g. a single pixel in image, a single character in a sentence.
- Output – only query is produced, it’s output is a piece of agent action/response. E.g. one item of one-hot vector.
- Expert – produces key, query and value.
Pros:
- The agent can handle input of variable dimensions
- Possible extensibility in # of experts
Cons:
- Bad scalability – O(N2) in # of experts
- Very sensitive hyper parameters of attention – attention sharpness (softmax multiplier) and key/query dimension are task specific
Index of GoodAI Grants
For completeness, here is a brief index of research projects supported by GoodAI Grants, which we earlier attempted to map together with the agent desiderata, Badger principles, and GoodAI’s own work. For more details see the GoodAI Grants page.
A) Research by Pauching Yap focuses on Bayesian Online Meta-Learning (BOML) for continual & gradual learning with avoiding catastrophic forgetting.
Core research topics:
- Extend the BOML framework [40] to support dynamic architectures for a wide range of tasks
- Handle sequential task learning on different neural network topologies
- Fit the BOML framework to Badger architecture (encourage expert communication for quick adaptation)
- Replace a hand-crafted inner loop adaptation by a learned inner loop learning rule
B) Research into Self-improving Modular Meta-learning led by Ferran Alet, aims to build a scalable compositional meta-learner that shows combinatorial generalization and scalability.
The research draws inspiration in Dynamic Programming algorithms for parsing (handling exponentially many combinations in polynomial time) and experiments with few-shot extrapolation on thousands of small analogical reasoning tasks.
Core research topics:
- Compositional optimization
- Ability to extrapolate to novel inputs
- Ability to generalize to larger programs
- Self-improvement through the discovery of internal structure
C) Research led by Deepak Pathak, Generalization Driven by Curiosity and Modularity, aims to build a Badger-like modular learner using curiosity and unsupervised learning for learning a general learning / adaptation policy. It would address generalization across different tasks and different environments in a modular system, driven by curiosity and modularity, with a zero-shot planning component.
Core research topics:
- Decentralized model-based modular dynamics, with a model built out of a single, reusable module (aka Badger expert)
- Environment as an agent: the environment will also be composed of the same modules as the agent
- Generalization via Unsupervised (Self-Supervised) Curiosity and Modularity: curiosity formulated as prediction error
- Modular message passing as a general adaptation method; applications: vision, language modelling, protein folding
D) Compositional Framework for Multi-agent Systems Based on Information Geometry , led by Martin Biehl and Nathaniel Virgo, aims to provide further theoretical analysis on why modular learning might be beneficial for scalability, generalization and solving multiple goals.
The goal is to develop an information geometry theory of multi-agent systems to: 1) increase understanding of existing algorithms and their applicability, 2) develop novel methods for multiagent learning. The core technique will be figuring out the distance between policies and goals on manifolds of joint probability densities.
Core research topics:
- Multiple, possibly competing goals
- Coordination and communication from an information theoretic perspective
- Dynamic scalability of multi-agent systems
- Dynamically changing goals that depend on knowledge acquired through observations
E) Department of Software Technology TU Delft. Of particular interest to GoodAI is the work of Dr. Wendelin Böhmer on Generalization in Distributed Badger Architectures. Details here.
F) Tomas Mikolov in the project Emergence of Novelty in Evolutionary Algorithms, would like to find out a simpler way for creating/encouraging novelty compared to original research on novelty search [49] and develop techniques where complexity keeps increasing indefinitely without external supervision. Such models can then be the basis for life-long learning systems.
Core research topics:
- Reproduce original experiments without explicitly defining novelty
- Behavioral novelty will emerge as a by-product of how the environment and objective function are defined
- Agents which do behave differently than the rest of the population will be rewarded
G) Lisa Soros in the project Open-ended learning environment for an open-ended learner would like to build an open-ended learning environment as a simulated artificial chemistry and create an agent capable of open-ended improvement within this environment. No explicit reward signal and no prior domain knowledge are given.
In this artificial chemistry world, reactions between molecules produce new molecules, leading to a potentially boundless and complex generative system.
Core research topics:
- How to construct the open-ended chemistry
- How to construct (interacting) agents that are capable of defining and acting on their own dynamic goals in absence of an explicit reward signal
H) To be announced…
I) Research by Kai Arulkumaran will focus on using open-ended algorithms to generate video game content. The project will test open-endedness in computational creativity and human-machine collaborative design, and provide insights into the role of multi-agent interactions in open-ended, lifelong learning.
Core research topics:
- Building on investigator’s previous work: research into Generative Adversarial Networks and applying a modification of the Minimal Criterion Coevolution (MCC) algorithm [56] to generate digital art. Unlike art, however, video game content must satisfy additional constraints of functionality to be appealing to players. These constraints would provide additional pressure towards more complex generations.
- Extending the algorithm’s multi-agent interactions beyond pairwise interactions, which are customary for MCC, and investigating the use of meta-learning for open-ended processes.
Closing Remarks and Next Steps
The focus of our research is the creation of a lifelong learning system that is able to gradually accumulate knowledge, effectively re-use such knowledge for the learning of new skills, in order to be able to continually adapt, invent its own goals, and learn to achieve a growing, open-ended range of new and unseen goals in environments of increasing complexity.
We will continue to investigate a number of avenues towards this goal internally via Manual and Automatic Badger as well as through GoodAI Grants that fund research of vital importance to topics we deem essential to the progress of Badger-like systems.
The above roadmap should provide a glance into our current state of mind while outlining our ongoing efforts towards scaling up our research and expanding into a wider community in order to direct and focus research efforts that we believe will get us closer to agents with such levels of autonomy that they will start becoming useful beyond the simple playing of computer games or generation of pretty pictures and sensible prose.
To join the community, check out goodai.com/goodai-grants and reach out to us.
References
[1] M. Rosa et al., “BADGER: Learning to (Learn [Learning Algorithms] through Multi-Agent Communication),” Dec. 2019, [Online]. Available: https://arxiv.org/abs/1912.01513v1
[2] S. Hochreiter, A. S. Younger, and P. R. Conwell, “Learning to Learn Using Gradient Descent,” in Artificial Neural Networks — ICANN 2001, 2001, pp. 87–94.
[3] J. Schmidhuber, “Evolutionary Principles in Self-Referential Learning. On Learning now to Learn: The Meta-Meta-Meta…-Hook,” Diploma Thesis, Technische Universitat Munchen, Germany, 1987.
[4] T. Hospedales, A. Antoniou, P. Micaelli, and A. Storkey, “Meta-Learning in Neural Networks: A Survey,” arXiv, Nov. 2020, [Online]. Available: https://arxiv.org/abs/2004.05439
[5] G. Bateson, Steps to an ecology of mind: Collected essays in anthropology, psychiatry, evolution, and epistemology. University of Chicago Press, 1973.
[6] J. Clune, “AI-GAs: AI-generating algorithms, an alternate paradigm for producing general artificial intelligence,” arXiv, Jan. 2020, [Online]. Available: https://arxiv.org/abs/1905.10985
[7] F. Alet, T. Lozano-Perez, and L. P. Kaelbling, “Modular meta-learning,” in Proceedings of The 2nd Conference on Robot Learning, Oct. 2018, vol. 87, pp. 856–868.
[8] F. Alet, E. Weng, T. Lozano-Pérez, and L. P. Kaelbling, “Neural Relational Inference with Fast Modular Meta-learning,” in Advances in Neural Information Processing Systems, 2019, vol. 32.
[9] K. Khetarpal, M. Riemer, I. Rish, and D. Precup, “Towards Continual Reinforcement Learning: A Review and Perspectives,” arXiv, Dec. 2020, [Online]. Available: https://arxiv.org/abs/2012.13490
[10] R. Hadsell, D. Rao, A. A. Rusu, and R. Pascanu, “Embracing Change: Continual Learning in Deep Neural Networks,” Trends Cogn. Sci., vol. 24, no. 12, pp. 1028–1040, Dec. 2020.
[11] R. Aljundi, “Continual Learning in Neural Networks,” arXiv, Oct. 2019, [Online]. Available: https://arxiv.org/abs/1910.02718
[12] R. Volpi, “The short memory of artificial neural networks,” Naver Labs Europe, Jul. 10, 2020. https://europe.naverlabs.com/blog/the-short-memory-of-artificial-neural-networks/ (accessed May 02, 2021).
[13] K. Khetarpal, R. Wang, and F. Behbahani, “Continual Reinforcement Learning – WiML ICML Unworkshop,” 2020. https://sites.google.com/view/continual-rl/home (accessed May 02, 2021).
[14] K. O. Stanley, “Why Open-Endedness Matters,” Artif. Life, vol. 25, no. 3, pp. 232–235, Aug. 2019.
[15] K. O. Stanley, L. Soros, and J. Lehman, “Open-endedness: The last grand challenge you’ve never heard of,” AI ML, Dec. 2017.
[16] V. G. Santucci, P.-Y. Oudeyer, A. Barto, and G. Baldassarre, “Editorial: Intrinsically Motivated Open-Ended Learning in Autonomous Robots,” Front. Neurorobotics, vol. 13, 2020.
[17] P.-Y. Oudeyer, A. Baranes, and F. Kaplan, “Intrinsically Motivated Learning of Real-World Sensorimotor Skills with Developmental Constraints,” in Intrinsically Motivated Learning in Natural and Artificial Systems, G. Baldassarre and M. Mirolli, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2013, pp. 303–365.
[18] D. Hafner et al., “ICLR 2019 Task-Agnostic Reinforcement Learning Workshop,” 2019. https://tarl2019.github.io/ (accessed May 02, 2021).
[19] D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell, “Curiosity-Driven Exploration by Self-Supervised Prediction,” in Proceedings of the 34th International Conference on Machine Learning – Volume 70, Sydney, NSW, Australia, 2017, pp. 2778–2787.
[20] R. Sekar, O. Rybkin, K. Daniilidis, P. Abbeel, D. Hafner, and D. Pathak, “Planning to Explore via Self-Supervised World Models,” in Proceedings of the 37th International Conference on Machine Learning, Jul. 2020, vol. 119, pp. 8583–8592.
[21] V. Nagarajan, A. Andreassen, and B. Neyshabur, “Understanding the failure modes of out-of-distribution generalization,” presented at the International Conference on Learning Representations, 2021.
[22] V. Garg, S. Jegelka, and T. Jaakkola, “Generalization and Representational Limits of Graph Neural Networks,” in Proceedings of the 37th International Conference on Machine Learning, Jul. 2020, vol. 119, pp. 3419–3430.
[23] C. Lu, Y. Wu, J. M. Hernández-Lobato, and B. Schölkopf, “Nonlinear Invariant Risk Minimization: A Causal Approach,” arXiv, Feb. 2021, [Online]. Available: https://arxiv.org/abs/2102.12353
[24] K. Zhou, Z. Liu, Y. Qiao, T. Xiang, and C. C. Loy, “Domain Generalization: A Survey,” arXiv, Mar. 2021, [Online]. Available: https://arxiv.org/abs/2103.02503
[25] K. Xu, M. Zhang, J. Li, S. S. Du, K.-I. Kawarabayashi, and S. Jegelka, “How Neural Networks Extrapolate: From Feedforward to Graph Neural Networks,” presented at the International Conference on Learning Representations, 2021.
[26] L. Ziyin, T. Hartwig, and M. Ueda, “Neural Networks Fail to Learn Periodic Functions and How to Fix It,” in Advances in Neural Information Processing Systems, 2020, vol. 33, pp. 1583–1594.
[27] L. Franceschi, P. Frasconi, S. Salzo, R. Grazzi, and M. Pontil, “Bilevel Programming for Hyperparameter Optimization and Meta-Learning,” arXiv, Jul. 2018, [Online]. Available: https://arxiv.org/abs/1806.04910
[28] S. Dempe and A. Zemkoho, Eds., Bilevel Optimization: Advances and Next Challenges. Springer International Publishing, 2020. doi: 10.1007/978-3-030-52119-6.
[29] E. Rezende, G. Ruppert, T. Carvalho, F. Ramos, and P. de Geus, “Malicious Software Classification Using Transfer Learning of ResNet-50 Deep Neural Network,” in 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), 2017, pp. 1011–1014.
[30] A. S. B. Reddy and D. S. Juliet, “Transfer Learning with ResNet-50 for Malaria Cell-Image Classification,” in 2019 International Conference on Communication and Signal Processing (ICCSP), 2019, pp. 0945–0949.
[31] M. J. Hannafin, C. Hall, S. Land, and J. Hill, “Learning in Open-Ended Environments: Assumptions, Methods, and Implications,” Educ. Technol., vol. 34, no. 8, pp. 48–55, Oct. 1994.
[32] R. Wang, J. Lehman, J. Clune, and K. O. Stanley, “Paired Open-Ended Trailblazer (POET): Endlessly Generating Increasingly Complex and Diverse Learning Environments and Their Solutions,” arXiv, Feb. 2019, [Online]. Available: https://arxiv.org/abs/1901.01753
[33] R. Wang et al., “Enhanced POET: Open-Ended Reinforcement Learning through Unbounded Invention of Learning Challenges and their Solutions,” arXiv, Apr. 2020, [Online]. Available: https://arxiv.org/abs/2003.08536
[34] Cathy, Black and white cat clipart 12 cm. 2011. Accessed: May 13, 2021. [Online]. Available: https://www.flickr.com/photos/bycp/5501065862/
[35] Unknown, Badger PNG image with transparent background. 2021. [Online]. Available: https://pngimg.com/image/61803
[36] J. Newman, “Summaries of AI policy resources,” Future of Life Institute, 2021. https://futureoflife.org/ai-policy-resources/ (accessed May 13, 2021).
[37] R. Sutton, “The Bitter Lesson,” Mar. 13, 2019. http://www.incompleteideas.net/IncIdeas/BitterLesson.html (accessed May 14, 2021).
[38] I. Gemp, B. McWilliams, C. Vernade, and T. Graepel, “EigenGame Unloaded: When playing games is better than optimizing,” arXiv, Feb. 2021, [Online]. Available: https://arxiv.org/abs/2102.04152
[39] B. McWilliams, I. Gemp, and C. Vernade, “Game theory as an engine for large-scale data analysis,” Deepmind, 2021.
[40] P. Yap, H. Ritter, and D. Barber, “Bayesian Online Meta-Learning,” presented at the The Thirty-eighth International Conference on Machine Learning (ICML), 2021.
[41] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in International Conference on Machine Learning, 2017, pp. 1126–1135.
[42] N. Guttenberg and M. Rosa, “Bootstrapping of memetic from genetic evolution via inter-agent selection pressures,” arXiv, Apr. 2021, [Online]. Available: https://arxiv.org/abs/2104.03404
[43] M. Andrychowicz et al., “Learning to Learn by Gradient Descent by Gradient Descent,” in Proceedings of the 30th International Conference on Neural Information Processing Systems, 2016, pp. 3988–3996.
[44] L. Metz, N. Maheswaranathan, C. D. Freeman, B. Poole, and J. Sohl-Dickstein, “Tasks, stability, architecture, and compute: Training more effective learned optimizers, and using them to train themselves,” arXiv, Sep. 2020, [Online]. Available: https://arxiv.org/abs/2009.11243
[45] K. Gu, S. Greydanus, L. Metz, N. Maheswaranathan, and J. Sohl-Dickstein, “Meta-Learning Biologically Plausible Semi-Supervised Update Rules,” bioRxiv, p. 2019.12.30.891184, Dec. 2019, doi: 10.1101/2019.12.30.891184.
[46] L. Kirsch and J. Schmidhuber, “Meta Learning Backpropagation And Improving It,” arXiv, Feb. 2021, [Online]. Available: https://arxiv.org/abs/2012.14905
[47] M. Sandler et al., “Meta-Learning Bidirectional Update Rules,” arXiv, Apr. 2021, [Online]. Available: https://arxiv.org/abs/2104.04657
[48] A. Mordvintsev, E. Randazzo, E. Niklasson, M. Levin, and S. Greydanus, “Thread: Differentiable Self-organizing Systems,” Distill, vol. 5, no. 8, p. e27, Aug. 2020.
[49] A. Mordvintsev, E. Randazzo, E. Niklasson, and M. Levin, “Growing Neural Cellular Automata,” Distill, vol. 5, no. 2, p. e23, Feb. 2020.
[50] B. O. Koopman, “Hamiltonian Systems and Transformation in Hilbert Space,” Proc. Natl. Acad. Sci., vol. 17, no. 5, pp. 315–318, 1931.
[51] B. O. Koopman and J. v. Neumann, “Dynamical Systems of Continuous Spectra,” Proc. Natl. Acad. Sci., vol. 18, no. 3, pp. 255–263, 1932.
[52] A. S. Dogra and W. Redman, “Optimizing Neural Networks via Koopman Operator Theory,” in Advances in Neural Information Processing Systems, 2020, vol. 33, pp. 2087–2097.
[53] C. W. Rowley, I. Mezić, S. Bagheri, P. Schlatter, and D. S. Henningson, “Spectral analysis of nonlinear flows,” J. Fluid Mech., vol. 641, pp. 115–127, Dec. 2009.
[54] A. Vaswani et al., “Attention is All you Need,” in Advances in Neural Information Processing Systems, 2017, vol. 30.
[55] J. Lehman and K. O. Stanley, “Abandoning Objectives: Evolution Through the Search for Novelty Alone,” Evol. Comput., vol. 19, no. 2, pp. 189–223, Jun. 2011.
[56] J. C. Brant and K. O. Stanley, “Minimal criterion coevolution: a new approach to open-ended search,” in Proceedings of the Genetic and Evolutionary Computation Conference, 2017, pp. 67–74.





There seems to be a lot in common with
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer Azalia Mirhoseini Krzysztof Maziarz Andy Davis Quoc Le Geoffrey Hinton Jeff Dean
ICLR (2017)