A Standardization Release
The main purpose of the GoodAI LTM Benchmark has always been to serve as an objective measure for our progress in the development of agents capable of continual and life-long learning. However, we also want it to be useful for anyone developing agents of this type. In order to facilitate that, we have oriented this release to be easier to comprehend and produce more standardized results, which we expect to be easier to compare and analyze.
From the very first version of the benchmark, we have grouped the specific test instances in datasets or task types. For example, there is one dataset which is called “Shopping List”, from which we can draw an arbitrary number of different test instances that will evaluate the agent’s ability to remember a series of items and keep an updated version of the user’s shopping list.
In earlier releases, each test could result in an arbitrary number of score points and these points were not normalized. This led to potentially confusing situations, in which passing a highly complex test would give only a few points, while a much higher score could be achieved by just submitting the agent to several examples of the same simple test.
In contrast, now the scoring is normalized at different levels. First, each test score ranges from zero to one. Second, running several tests from the same dataset will result in an averaged score and a standard deviation for that dataset. This way, one can look at the global score knowing that it corresponds to exactly one point per dataset, which makes it easier to interpret. Additionally, running several tests from a single dataset provides valuable insight into how robust the agent’s performance is.
Introducing a standard configuration
One of our goals with this release is to make it straightforward for anyone to configure different levels of memory demand and also understand how demanding a specific configuration is. Most discussions about memory capabilities in LLM agents are currently centered around the context size of a particular LLM or how good the LLM is in retrieving needles from such context. While we want to ultimately move away from those implementation-centric terms, we believe that using words that the public is already familiar with will make it much easier to understand the scope of the LTM Benchmark and whether a specific agent might have any chance at it or it is technically incapable of succeeding.
For these reasons, we have simplified the configuration related to the conversation length and the amount of information given by the tests, and we have reduced the corresponding parameters to just two: the maximum memory span and the number of needles in a test. The first is a global parameter that affects all tests, and the second is a parameter that can be tweaked for each dataset in order to calibrate the task difficulty.
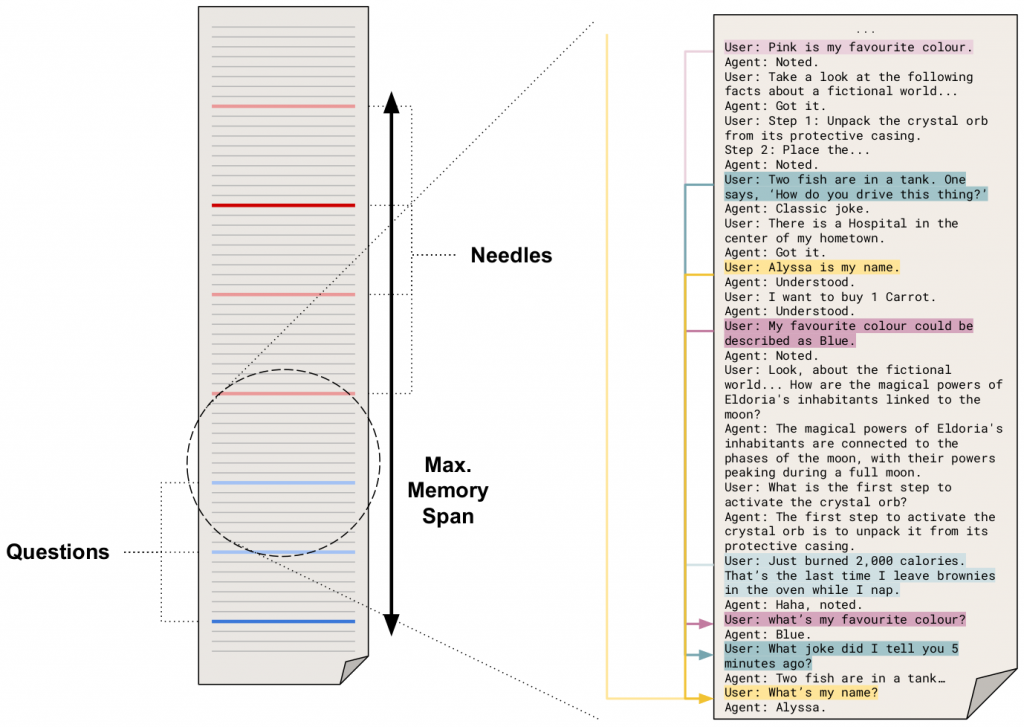
Memory span
In the context of a test, in which the agent is given some information and finally asked a question about it, the memory span refers to the amount of memories that the agent must consider or the extent to which the agent must search for relevant information in order to correctly answer that question. Translating the concept to a written conversation, we can define the memory span as the amount of text that exists between the question and the first relevant piece of information.
The configuration of the LTM Benchmark now contains a maximum memory span, which sets a target to how much space a test should take in the conversation. Taking that value as a reference, our scheduling system aims to distribute the tests messages along that space, covering at least 90% of the memory span, but also trying that no test exceeds that mark. However, such things might inevitably happen sometimes, and the system will display a warning both in the console and in the final report. From a technical standpoint, this means that any LLM with a context size greater than the maximum memory span set in the benchmark configuration will usually have all relevant information in its context. On the other hand, for agents using LLMs with smaller context sizes, the importance of their LTM systems will be highlighted when put in contrast to the actual memory requirements.
Number of needles
The so-called needle in a haystack tests are commonly conducted in order to assess the retrieval accuracy of different LLMs. In this setup, a needle is a short sentence either being out of place with respect to the surrounding text, or containing key information towards providing a correct answer to the test question.
In the LTM Benchmark, all tests are defined by a set of needles and questions. The needles are messages containing relevant information, which can be because they contain part of the answer to future questions, or because they are distractors injected intentionally by the test to assess the agent’s memory abilities. Most tests will let you adjust the difficulty by setting the amount of needles. Finally, the test questions are posed in a way that the answer is affected by the content of the needles placed before it.
The scheduling system of the LTM Benchmark evenly spaces out all these questions and needles across the configured memory span, interleaving messages from different tests and injecting irrelevant information as needed. The result is a seamless and natural conversation between the agent and our virtual tester, a conversation that is hundreds or thousands of tokens long, but in which the information required to provide the right answer to any question is not further away than the maximum memory span set in the configuration.
Results
With this release, we have changed the structuring and scoring of the tests. With that, we have rerun the tests to see how GPT4 and Claude-Opus stack up against our Claude and GPT powered LTM agents.
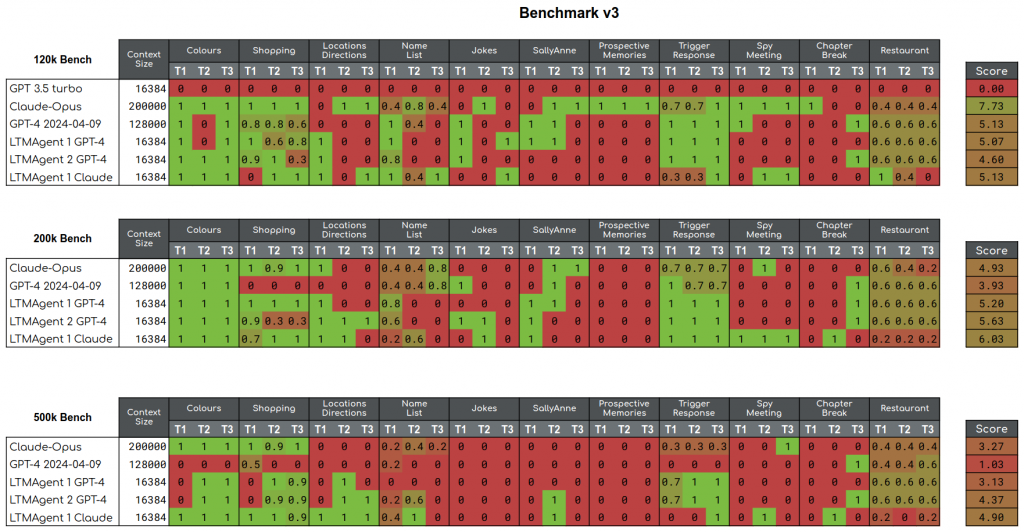
For this release, we ran three benchmarks. Each of the individual tests (i.e the script statements in the tests) were identical across the three benchmarks, with the only difference being in the number of tokens in the memory span, and hence the number of tokens between the needles and questions.
The selected memory spans were 120k, 200k, and 500k. These were chosen based upon the context sizes of GPT4 (128k) and Claude Opus (200k). For those LLMs, we expected to see a smooth decrease in the obtained scores. We contrast with the LTM agents, driven either by GPT4 or Claude Opus. We expected the LTM agents to perform under the LLMs when the memory spans fit into the LLM context, but also maintain their performance as the memory span increased.
The results show that the LLM scores indeed decrease as the memory span widens. For the LTM based agents, the scores also decrease, but more slowly than those of the LLMs. Curiously, the 200k benchmark sees a bump in the scores in the LTM agents compared to the 120k benchmark. As of publishing, we are unsure why this is the case, but hypothesize that the increased memory span spaces the needles out more, which helps the semantic memory by requiring it to embed only a single needle at a time, and not grouping needles together under a single embedding.
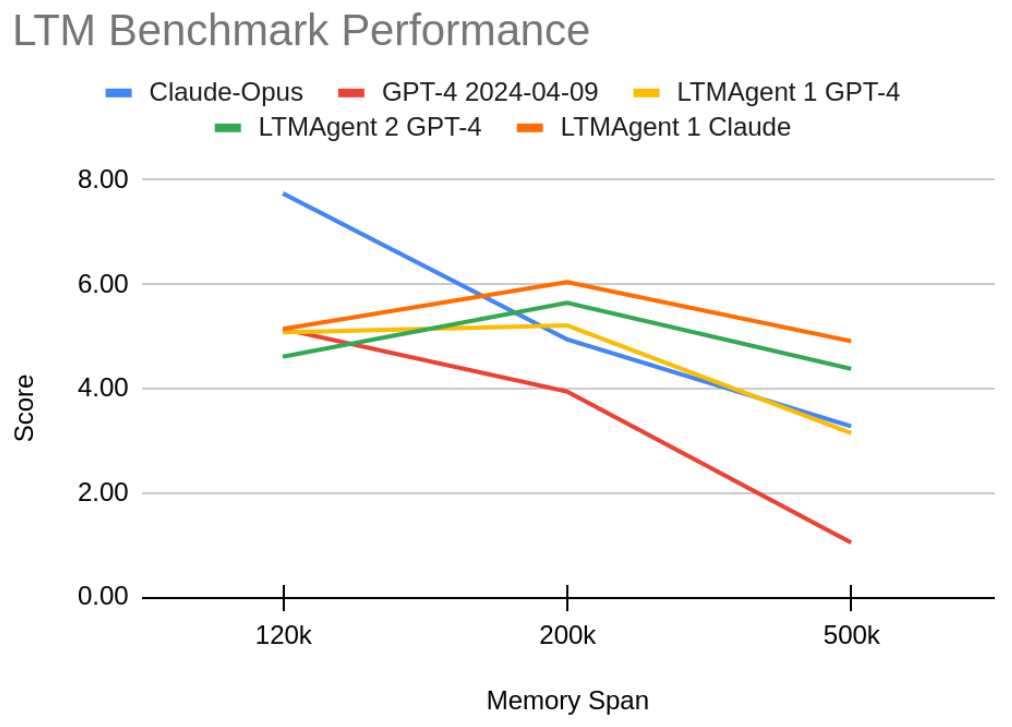
To comment on some specific tests and agents:
- The colours test is generally solved very easily by the agents across all benchmarks, because the only information that matters is the latest colour, which is the needle just before the question. Even with memory spans this large, the gap between that needle and the question is often smaller than the context size of the agent.
- Prospective memories have been improved since the last blogpost, but the only agent that can solve it is Claude Opus on the 120k benchmark.
- Claude Opus’ performance on the Restaurant task varies wildly. It is the only agent to get full marks on a test example, but its mean performance is below that of the other agents.
- The Claude Opus models have a tendency to restate information during the tests. For example, in the 500k shopping task, the agent repeats the current shopping list whenever a change is made, which keeps the whole list in context for the test. Similarly, LTMAgent1 Claude on the 500k benchmark does this for location directions tests.
- We tested GPT3.5, which tends to struggle on the tasks under ideal conditions, but scoring a flat 0 on the 120k benchmark disqualified it from the more difficult tests.
What’s next?
We believe that the benchmarks here are in a good place and present a significant challenge to prospective LTM candidates. We will continue to develop the benchmark by adding new tasks, and use these benchmarks to help develop our next iterations of LTM agents.
Get Involved
Building on these last 3 iterations of the benchmark, we have authored a paper describing it in full, which has been published at NeurIPS 2024: https://openreview.net/pdf?id=twFlD3C9Rt
As always, these benchmarks and their corresponding results are available as open source on our github at https://github.com/GoodAI/goodai-ltm-benchmark/releases.
If you are interested in LTM systems and wish to see how your solutions stack up, please try it and let us know. Additionally, if you have results, or any ideas for new tests, raise an issue in the repository or create a pull request.
Here are other ways to follow or get in touch with us:
- LTM Benchmark Github: https://github.com/GoodAI/goodai-ltm-benchmark
- Discord: https://discord.gg/Pfzs7WWJwf
- Twitter: https://twitter.com/GoodAIdev
- Facebook: https://www.facebook.com/GoodArtificialIntelligence/
- LinkedIn: https://www.linkedin.com/company/goodai/





Leave a comment