Most modern AI scales with the availability of data – to improve its performance or behavior requires more and more data taken from the world. The promise of Badger is to give scalable computational resources, as increasing numbers of experts could be added at runtime. So how do we turn that into an advantage, if data is the limit? One kind of method that does scale with compute is AI that integrates some sort of search component over a model of the world – for example, the successes of Monte-Carlo Tree Search and AlphaGo. However, in those games, a perfect model of the world can be provided. For AI that will generalize and scale to real-world, formerly unseen problems, we need to become good at learning such models.
The videos above are examples from a model learned from videos of a particle simulation. In particular, this is a model that can generate not just one future but an entire distribution of possible futures – a distribution that could be searched in parallel by multiple nodes, with their discoveries then networked together via communication in order to formulate a decision.
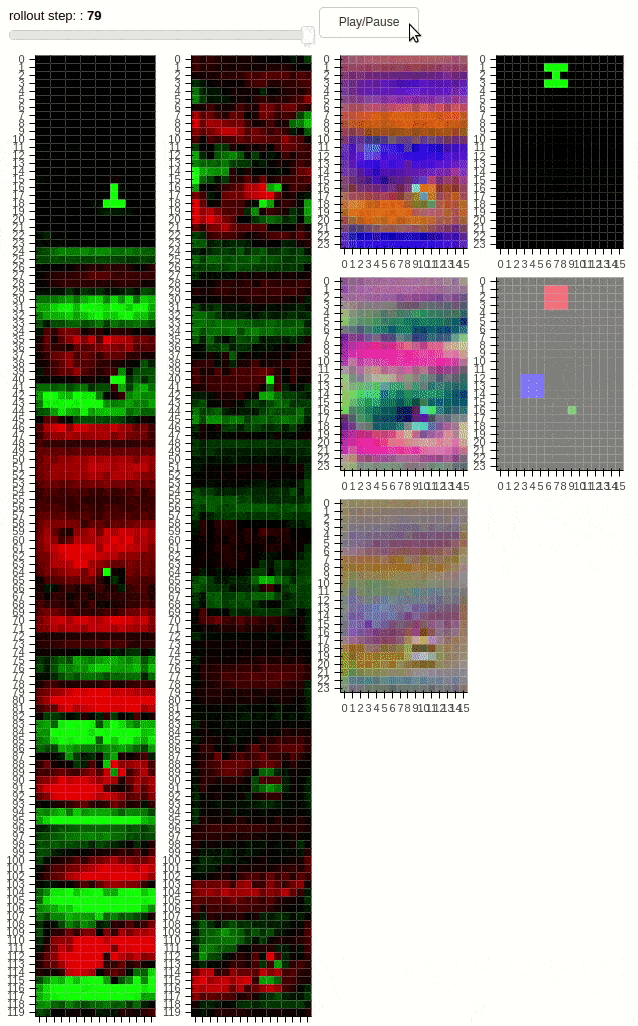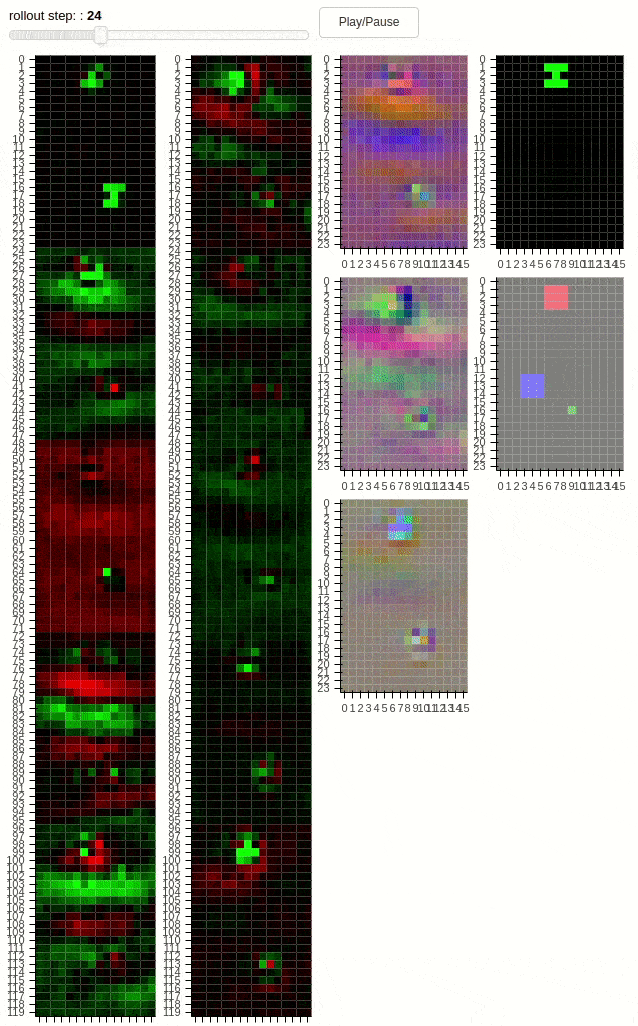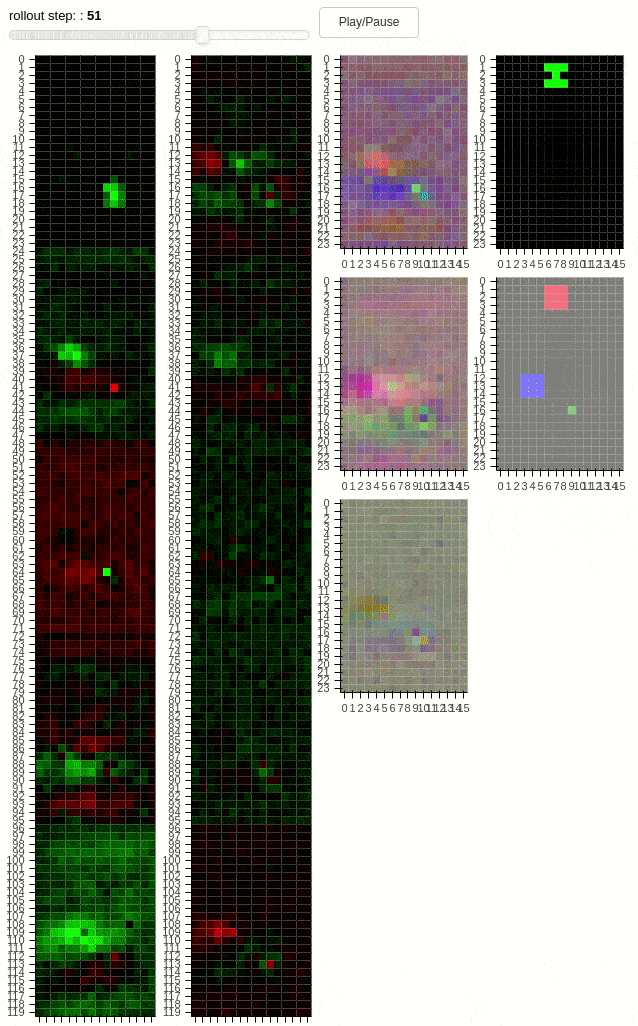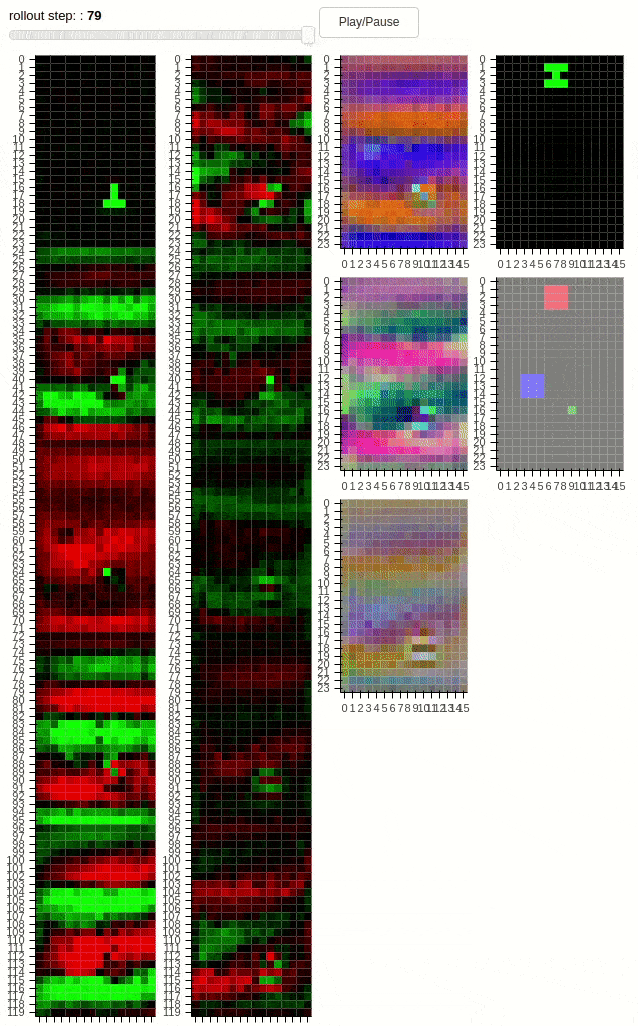
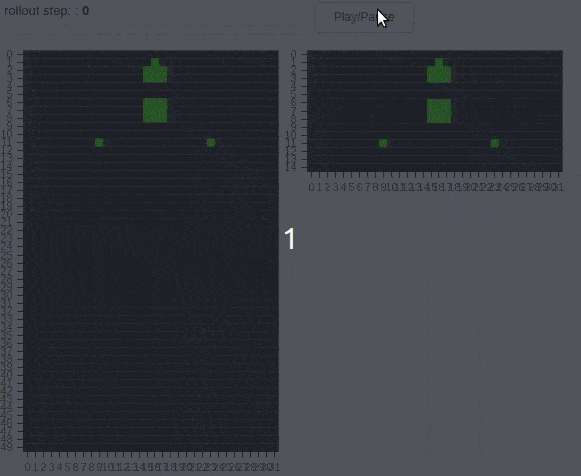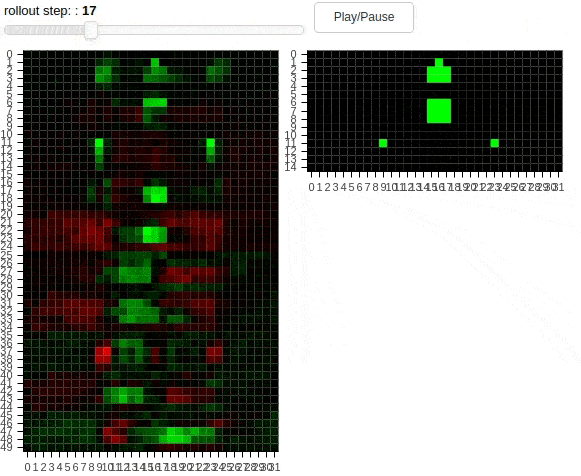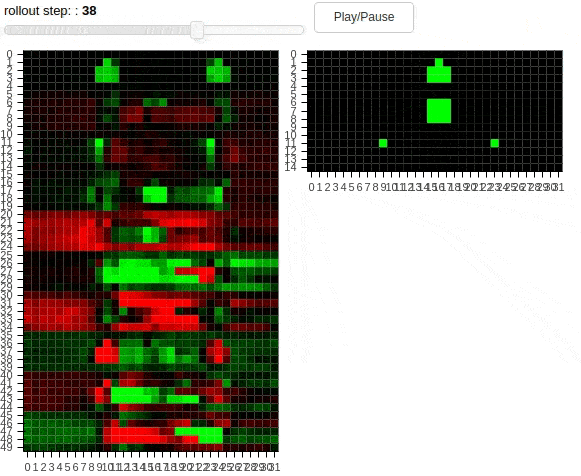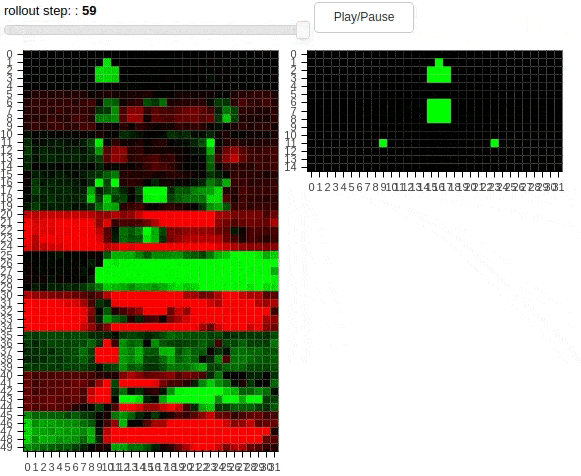
The animations above shows 10 layers of a cellular automaton evolving over time. The task is to copy the pattern from the middle to one of the dots – not both. Thus, the distributed agent has to learn a coordination strategy to determine which dot will be active. The second animation demonstrates a “transform” task, where the pattern has to be modified during the copying process. Additionally, regularization in form of cell activation zeroing is present. The policies unfolding above have been found by SGD.
The cellular automata displayed in the earlier section demonstrated the ability to capture and simulate a model of the world in a distributed fashion. A more direct approach, often fruitful in deep learning applications, is learning a task solver in an end-to-end manner: provided with inputs and the desired outputs, the solution (copy pattern, transform pattern, etc.) is found by backpropagation. In the case of cellular automata with a shared cell policy, this naturally makes generalisation to different tasks easier, because the solution needs to be modular and distributed over varying network sizes.
Having a modular policy that can be distributed on a large scale and solve different tasks is helpful, but is only the first step towards general AI. The next and necessary step is to allow the policy to expand the range of tasks that it can solve through accumulation and reuse of experience. These principles together form the foundation of Badger architecture.





Leave a comment