Note: This post is part of a series of blogposts on the LTM benchmark. In the first post we outline our motivation for the benchmark, and in the next post we describe the current results.
At GoodAI, we are committed to developing agents that are capable of continual and life-long learning. As part of our efforts, we have previously open-sourced the GoodAI LTM Benchmark, a suite of tests aimed to evaluate the Long-Term Memory (LTM) abilities of any conversational agent. In this benchmark, all tasks take place as part of one single very long conversation between the agent and our virtual tester. The benchmark interleaves information and probing questions from different tasks, albeit taking special care of weaving them together into a natural conversation.
LTM = Long-Term Memory
As a direct consequence of our research in agents with LTM, the GoodAI LTM Benchmark is in constant evolution. To us it represents an invaluable tool for evaluating our agents and validating our hypotheses. Additionally, it helps us characterize the ways in which the distinct agents fail and therefore it provides us goals to aim for. In the GoodAI LTM team we regard the GoodAI LTM Benchmark as a moving goal post, and by introducing new tasks and features we are continuously pushing that goal post away, because what is a goal post worth if it is easy to reach?
New features
With every new feature, we try to make the GoodAI LTM Benchmark not only more and more challenging, but also more realistic. The thing about benchmarking LTM is that you need your tests to be long, very long. So you either introduce a ton of dummy interactions for the sole sake of filling up the conversation, and accept that all those tokens are wasted resources, or you start interleaving the tasks and weave them into a seamless and natural conversation (like we do). We are always doing our best to minimize the amount of wasted tokens, whilst keeping the conversation natural and making sure that the agent can follow along.
Dynamic Tests
In previous versions, tests were mostly static, which means that there is a fixed script to follow, and absolutely no deviation from that script is expected nor accounted for. A static test is defined by:
- A script containing the sequence of messages that will be delivered to the agent.
- A list of waits that tell the virtual tester how long or for how many tokens to wait before delivering the next script line.
- A list of flags of the same length, which determines whether a script line is a question or just an informative message.
- A list of expected answers, one for each question in the script.
However, we were planning to add a couple of test scenarios that required more flexibility, and whose content should feel more natural than a bunch of predefined messages. We wanted to be able to react to the agent’s responses, incorporate part of those responses into the test and have the agent participate more actively in the task. As a result, we implemented the dynamic tests, which are Python generator functions that deliver one action at a time (a message, a question or a wait), and incorporate the whole scripting and evaluation process in its code. Let’s go through a quick example:
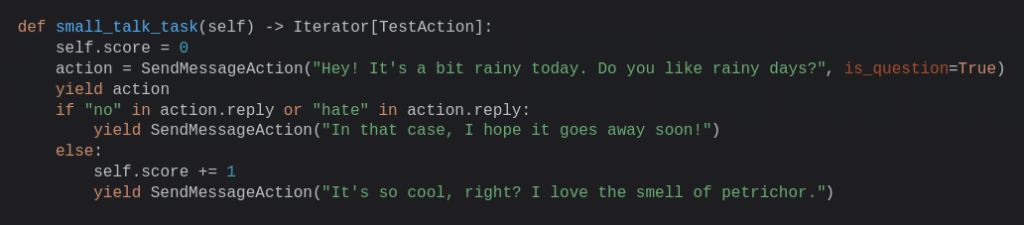
In this example task, we engage in some small talk with the agent and we give it points for going along with the conversation. We tell the benchmark runner that we want to send the message “Hey! It’s a bit rainy today. Do you like rainy days?”, and after delivering the action we have access to the agent’s response and other metadata through the same action object, which lets us compute the scoring and drive the conversation thread. The task scheduler might choose to do many things before going back to your task, like starting another task, let some tokens flow or some time go, but you really don’t care about it, because when the benchmark is ready to continue with your task, you will find yourself at the exact point in the function where you left it and with all the information that you need to continue with the task. Additionally, you can use that information to enrich your messages, evaluate the agent’s performance, or even to branch out! In this case, we simply change the message depending on whether the agent likes rainy days or not, but we could start one of two completely different conversations. In any case, the level of complexity is up to you!
Moreover, we have kept things simple and low-level in this example, but in reality we have equipped the code with all sorts of shortcuts and helper functions, like say or wait, which will make your life much easier and help you better craft the task that you have in mind. Check all the details about how to implement a dynamic test in the GitHub repo.
Percentage Waits
Part of our plans for this release was to have tasks that could span across the whole benchmark conversation. For example, one task could give the agent some information at the very beginning, some more in the middle, and finally we would ask the agent to connect the dots at the very end of the conversation. However, we only had token and time waits at the time, so we would’ve had to precisely estimate in advance the total amount of time or tokens of the benchmark, which didn’t sound very appealing nor elegant. Instead, what we needed was a way to point to any position in the conversation and be able to say “I want to wait until here”.
While we haven’t managed to do that just yet, we came up with the percentage waits, which let tests stay on hold until some portion of the tasks has completed. This way, a test can wait until 15% of the tasks in the benchmark have finished, or 40%, or all tasks (we will get back to that later). Although this method doesn’t guarantee much precision, it does allow tests to roughly specify where in the whole conversation they require their messages to be delivered. This poses a significant improvement in terms of naturalness and dynamism of the tests.
Certain combinations of waits can originate deadlocks though. For example, two tests waiting for the same percentage or a test waiting for 100% of the tasks to complete. However, we don’t let that happen because we simply don’t take wait percentages to the T, but mostly as suggestions for approximate message delivery points. Actually, all waits behave this way, but we have sophisticated prioritization rules to avoid it having a negative impact on the tests. Usually, interleaving tasks is enough to satisfy the waits, but when all tests are waiting we fall back to the following prioritization policy:
- Time waits go first. If a test is waiting for some time to go by, we can simply fast-forward the system clock. The agent won’t know =)
- Token waits go second. Most token waits are satisfied by other tests that run concurrently, but when there are no other tests to run we can always resort to a non-productive task. In our case, we simply give the agent some unstructured text and we ask it to give it back to us in JSON form. That will keep it busy =)
- Percentage waits go last. We try to keep all tests happy, but you can’t get blood from a stone, so in these cases we just set to run the test with the lowest percentage wait and, if there’s a tie, we roll a dice. It was merely a suggestion to begin with =)
New tasks
In this version of the GoodAI LTM Benchmark we have introduced three new tasks, which heavily focus on two aspects of the LTM that are frequently bypassed in most existing benchmarks. Two of the tasks are heavily centered around the process of information integration, which is the act of not only gathering different pieces of information, but also connecting them together and establishing the right relationships between them and the current knowledge. Information integration is a key element of continuous learning and it is what allows leveraging past abilities in order to produce novel, more complex skills and learn faster and better. In addition, we have also added one task that requires a kind of memory retrieval for which current RAG systems are not well prepared. Commonly, queries and memories are embedded into a semantic space, and the retrieval of potentially-relevant information happens attending to the distances in such space. However, there are some cases where the connections are subtle or indirect, and that is precisely where current RAG systems tend to fail.
Spy Meeting Task
In this task, the agent is contacted by three different undercover agents at three different times. Each person will give the agent a key piece of information in the form of a cryptic message, and the agent’s job is to figure out what these messages really mean. After the agent has received all these messages, it will be required to decode them into the details of a clandestine appointment: when and where it will take place, and what the agent shall bring. It might not seem a lot, but it’s actually quite challenging for current RAG systems to find information that’s not clearly similar semantically, and the sentences are like needles well spread out across the 330k token conversation.
Needle = as in the “finding a needle in the haystack” analogy
ChapterBreak
Speaking of needles, the thread of a plot is sometimes quite subtle and nuanced. In ChapterBreak, the agent is presented with up to 10 chapters of a fan-fiction book, and then it’s questioned about the possible continuations. In addition to the chapters, we give the agent 6 possible beginnings as candidates for the next chapter, and we ask the agent to say what option looks more like the true next-chapter beginning.
We have found this task to be extremely challenging for current LLM agents. Even if they manage to fit the whole text in their LLM’s context window (which is more than 8k tokens), agents often miss the key information, or they get confused by the rest of the text, or they simply don’t seem to understand the plot and pay attention to irrelevant details. Additionally, in the original ChapterBreak dataset nearly half of the samples are not really solvable. Some chapters end abruptly, or switch characters, so that there’s just no way to tell what the right next-chapter is. We took the time to read through 7 samples (around 70 book chapters plus their corresponding continuations) and we selected 4 which do have a solution.
The Restaurant Task
We talked before about our intention of making the benchmark tasks as natural as possible, and this task is right now our best example to date. In the restaurant task, the agent is asked to engage in some roleplaying and interact with a waiter as if it were a customer at a restaurant. However, the agent is unaware that the experience will be far from flawless. During the course of the meal, the agent will see its order being bounced back, at some point the waiter will bring the wrong dish and a couple of other mishaps will also occur at very distant points in the conversation. The agent will be expected to navigate these situations gracefully by leveraging the available information. It will receive points for ordering something that is on the menu, for recalling the menu later on, for noticing any mix-up, etc. In order to accomplish this level of naturalness, we leverage the flexibility of the newly introduced dynamic tests, and this is actually a great point of reference if you are looking into implementing a dynamic test yourself.
Result Analysis
We have released two benchmarks thus far, making all the data we have publicly available. But the results are not just in the numbers. Here, we are going to look into the reports generated by the testing, analyse where models tend to fail, look critically at the robustness and validity of our current tests, and see where the benchmark is strong and where it is weak. To visualise the performance of the agents, we have a heatmap of the scores of the agents on each of the tasks.
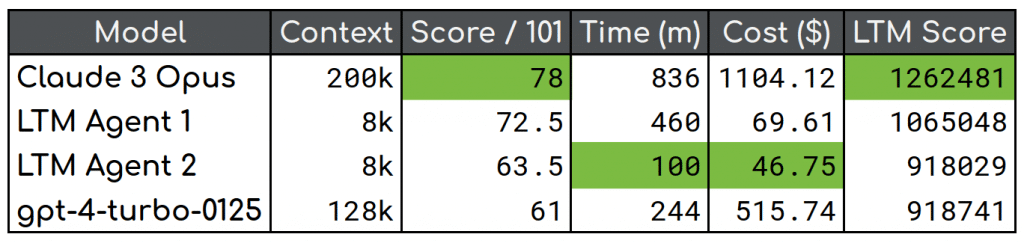
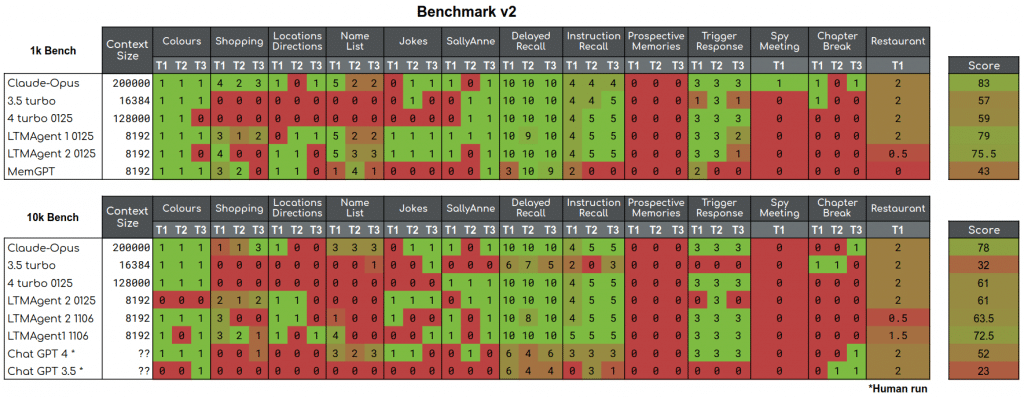
Tests
The tests we have released range from basic sanity tests to complex ones intended to push the models and their LTM capabilities (retrieval and reasoning over very large conversational histories). As of Benchmark 2, each test has a “reset message” which essentially tells the agent being tested that it should forget what has happened in the previously run test (to push the information integration – because the reset instruction influences all the following instructions). This is a common feature for all of the tests that we will discuss in this section.
Colours
The colours test is a simple test that should record the latest colour preferences of the test user. While the effective gap between the pertinent information (i.e. the last colour preference statement in the test) and the question is comparatively low compared to other tests, the complexity is introduced by the agent needing to keep track of changes in the preferred colour.
This task is generally fairly completable. Failures in this task come from poor attention, or the model not being able to reconcile the different contradictory statements made in the test. The 0125 version of LTMAgent2 on the 10k benchmark inexplicably fails, constantly saying that the favourite colour is pink.
NameList
NameList is a similar test to Colours where the test gives the agent a number of names that the tester should be known by. The difference from the Colours test, is that in this case, the question asks for all of the names that the tester has given the agent thus far.
This task has been quite challenging for two reasons, 1.) This task tests the information integration of all of the name statements given to the agent, and 2.) It tests the agent specifically disallowing information in the conversation if it is given before a reset statement in the conversation. An example of an agent failing on point 2 is in Claude3-opus on the 1k Benchmark. In this test, the agent gets all of Test1 correct, but in the subsequent tests, the agent leaks answers from the preceding test. In this case the agent has failed to attend to, or relate, the reset messages with the previous names given to it.
Jokes
The jokes test tells the agent a series of jokes, and then questions the agent about which joke was told at a particular relative point in the past. This test expects that there is some kind of timestamping of messages to the agent. Which the agent can then use as a reference point to look back farther in its context or memory.
This is understandably difficult for the pure LLM agents. Most of them guess the final joke that was said to them, which in one case is correct. The LTM equipped agents tend to score higher in this task on average, but it is still not reliably solved by them.
Shopping List
The Shopping list task presents the agents with items that should be added or removed from a shopping list. It is up to the agent to maintain this shopping list throughout the changes that are performed. Eventually, the agent is asked to recall the list in JSON form, and it is scored on the correctness of the items on the final list.
This is a good task for testing attention and information integration. For the LTM equipped models, better scores come from agents that have a scratchpad on which they can write the memories. Other agents relying only on semantic memory, can bleed items from a previous test, as they likely do not also retrieve the reset messages. For pure LLMs, an easy way they can solve the task is to maintain a list in the replies to messages with list changes as we have seen with GPT-4. However if they do not do this, the LLMs can have trouble integrating the information, even if the LLMs context is large enough to hold all of the changes made to the list. GPT-4, and Claude-Opus both encounter challenges in this task.
One potential weakness of the task is in some of the potentially ambiguous phrasing of messages in the task. An initial message of “I want to buy x” gives no explicit instruction to the agent, so it may not pick up on the need for it to save the items. On the other hand, this phrase doesn’t presuppose the method of solving the task. A sufficiently advanced agent would be able to pick out items that it had perhaps missed before upon realising that it should create a shopping list.
ChapterBreak
The ChapterBreak test makes use of a subset of the ChapterBreak dataset. There are three stories that the agent is given, one chapter at a time, and then they are given 6 possible continuations. The agent should return the number corresponding to what should be the correct continuation.
This is a very challenging task, and the only models capable of performing this are currently the LLMs with large enough contexts. LTM equipped agents do not currently appear to have the capability to systematically compare and contrast the original story with the potential continuations.
That said, the LLMs do not convincingly solve the task either. ChapterBreak is presented as the first tests and does not have filler tokens in between statements. This means regardless of the benchmark (1k or 10k), the agent is presented with the Chapterbreak tasks in the same way. You would therefore expect consistency in the LLM responses between those tests, but that consistency is not present. Claude-Opus achieves 2 correct answers on the 1k benchmark, and only 1 correct answer on the 10k. GPT-4 fares worse in that it either says it cannot speculate on what happens next, or says that it could, but since we specified that it should return a single number, it chooses the same “random” digit in all cases.
Trigger Response
The trigger response task instructs the agent to return with a response phrase in reply to a trigger that we send it. We tell it what we expect it to do, then test it with the phrase three times.
This task is one that is fairly straightforward for the agents. The agents tend to just repeat the text verbatim, or with very slight rephrasings.
This has a couple of flaws. In this case, there are two instances of the ‘illness’ example, and overall the task is not very difficult. One way to make the task more difficult would be to instruct the agent on several triggers at the same time, and test these triggers throughout the whole lifetime of the test.
SallyAnne
The SallyAnne test is a theory of mind test where the agent is given the events of what we frame as a television show. When the events have concluded, we ask the agent about a fact evident in the events or what one of the characters should think about a question.
The test itself has two fact based questions and one thought based question. The thought based question is the most difficult test for the agents. In one case, Claude-Opus actually proposed the correct answer, but talks itself out of the answer saying that it doesn’t know the thoughts of the person that moved the object.
One weakness of these tests is in the unevenness of the difficulty. The fact based tests are much easier than the theory of mind ones – In the table above, the second test in the theory of mind test. So further developments may ensure that the test that is retrieved from the dataset is actually a theory of mind test, and not one about the facts.
Spy Meeting
This dataset has the agent being informed that it will get three messages from three characters. Those three messages are given to the agents in semi-coded language, and the question asks the agent to reconstruct the meeting parameters given the clandestine messages. The question refers to the messages obliquely to try and confuse naive semantic search.
The oblique reference to clandestine messages does seem to confuse the agents, with only Claude-Opus and GPT-4 on the 1k benchmark managing to find all three messages GPT-4 however, declines to decode the message.
There is a decoding issue that arises from the fact that we use string matching to check them. If the agent declines to decode the message as in the case of GPT, even if it clearly has retrieved or attended to it, it will be marked as incorrect.
Restaurant
The restaurant task places the agent in the role of a customer in a restaurant. The test plays the part of a waiter and asks the agent for drink and food orders, apologies for a missing food item, brings an incorrect food item, and asks the agent about what it has ordered.
This test is very challenging for the agents. It is a dynamic test and has some amount of reactivity with the agent, but that reactivity is limited in scope. It is rare to see an agent get full marks on the test.
Due to it being dynamic, we use GPT-3.5 to process the responses from the agent and create the next script lines. This doesn’t always go as planned, as GPT-3.5 can sometimes oddly partition the responses from the agent which can result in incomprehensible orders. Furthermore, responses from Claude-Opus often go beyond that of the foreseen responses, with stage directions and physical responses added. Further iterations will try to gracefully account for these variances.
Prospective Memory
The prospective memory test is where we present a fake quote by a fake person and ask the agent to append the quote to the response to the nth statement from the user after the current one.
No agents pass this test. It appears to be very confusing for them. Current failures include the agent flat out refusing the task by saying that it cannot see the future and does not know what it will say, and the agent thinking that it should immediately make a collection of unrelated statements and append the quote to one of them.
A future version of this test will attempt to make the task more explicit for the agent so that it knows what it should do.
Locations Directions
This test gives the agents a list of locations in a town with positions relative to the previous location listed. In the end, the agent is asked to navigate from the initial location to the final one, passing through all or some of the listed locations.
To complete this test, the agent has to retrieve all of the locations and order them appropriately when listing them out. This is generally achievable by the agent, but in Benchmark 2, some bleed through is evident between tasks. In these cases, the agent repeats a direction from a previous task, which results in an error.
One failure is that these erroneous directions were not always caught. We previously used a GPT model for evaluation of the test, and it sometimes marks the test correct, even when it should not be. However, we now use a more advanced evaluation in which we play the instructions out, and see if the ending coordinates match where they are expected to be. This new evaluation method seems to work 100% of the time.
Delayed Recall
This test presents a list of 10 facts to the agent about a fictional world. The world is often a fantastical one. The agent is then given 10 questions about these 10 facts and is scored based on how accurate its answers are.
This test can expose when retrieval or attention failures. One example of a retrieval failure is in the answer to one of the questions for LTMAgent2-1106 10k. In this question, the agent also retrieves a reset message for this task and erroneously associates that reset message with the pertinent data, so it refuses to answer the question.
MemGPT also has very inconsistent retrievals for this task, and tends to hallucinate an answer or state that it does not know what the answer is.
Instruction Recall
Instruction Recall is similar to delayed recall in that there are a number of facts, in this case a list of instructions, that are presented to the agent and a number of questions that refer to those facts. The twist in this case is that the facts have an order, so we can ask relative questions such as “What step comes after x”.
The first test contains a clumsily phrased question “What is the final step after <step 8>”, which expects <step 10> as an answer, but most of the models return <step 9>. Interestingly, the exceptions to this are the LTMAgent variations which correctly recite <step 10> as the answer, but fail on another question in that test.
Models
Different agent implementations have distinct failure modes, and these failure modes point us to either flaws in their design or in the benchmarks themselves. Below we conduct an analysis of the results of two LLM agents (GPT-4 and Claude), and of our LTM Agent implementations, which feature an LTM memory management system and can work with less than a tenth of the context size and for a fraction of the cost. We have omitted from the analysis GPT-3-turbo, because it is merely a baseline to compare against and there is not much interesting to say about it, and MemGPT, because it looks like it was not ready to work in this regime and after some number of interactions it forgets how to communicate with the user (calling its send_message functions).
GPT-4-turbo
Despite its very long context of 128,000 tokens, we have found that the newer 0125 version has been significantly downgraded in terms of its functionality. Any attempt that remotely resembles us asking for personal information will quickly trigger a generic “as an AI I cannot do that” response. Because of this, the LLM fails 5 of the 13 tasks that comprise the benchmark.
The case of ChapterBreak is especially salient, since the LLM first gives the AI excuse, then follows on to say that it could suggest an option, but finally says that it wasn’t asked to do that, so it randomly chooses one. Spoiler alert: it always chooses “three”. In the case of our LTM Agents, we also noticed the lower performance when using the gpt-4-turbo-0125 as the core LLM, and the performance went back up when we switched back to gpt-4-turbo-1106.
Claude 3 Opus
Claude is the clear winner of the second version of the GoodAI LTM Benchmark, and it has been a huge step-up from the previous Claude 2, which achieved mediocre results in Benchmark v1. The new LLM has kept the 200,000 context tokens of the 2nd version, which already surpasses OpenAI’s 128,000 context size, but now it’s also more performant and its use of the attention seems more reliable and precise than its competitors. Claude’s attention mechanism seems not only better than GPT’s but also different, given the novel failure modes that it presents. It retains surgical precision all over the context, but it struggles with sequentiality.
Despite its overall proficiency, Claude finds its kryptonite in bringing together information and instructions from different places of the conversation (information integration). As it might be expected, this weak point makes an appearance in tasks that test precisely that memory skill, like when Claude struggles to recall the list of names from the Name List task, but it also shows up in other scenarios. While in previous versions of the benchmark we reset the agent’s memory between potentially conflicting tasks, now we simply ask the agent to disregard the conflicting information. With Claude, this results in the agent taking the Shopping List task while roleplaying as a customer at a restaurant, or refusing to provide an answer because we told it to disregard similar but past information a while ago. And by the way, Claude gets so much into the role of a customer, that it even underperforms intentionally, just for the sake of pretending to be human.
The safety measures are also a remarkable handicap, although it’s often feasible to avoid those limitations by extensively explaining the benchmarking situation. Claude is largely cautious when it comes to infringing copyrights or making assumptions about personal opinions. Besides that, you might have noticed its high score in the Jokes task, but that’s just Claude being lucky, not that it internally keeps track of time or anything like that.
LTM Agents
To recap, we shipped the first version of the GoodAI LTM Benchmark with two early versions of LTM agents. We did so mainly because we wanted to showcase the benefits of having an LTM system, but these agents turned out to be a good baseline for the new version of the benchmark. Both agent versions have a core LLM with an 8k token context, and have access to a semantic database of memories, but LTM Agent 1 also has a scratchpad that it can leverage for tracking more dynamic information. However, and because it has to do many inference cycles in order to manage the scratchpad, the LTM Agent 1 is around 5 times slower than LTM Agent 2.
We tried using GPT-4-0125 as the core LLM, but it resulted in a significantly worse performance. One exception is the shopping task, for which the new GPT-4 version helps the agent score better. This leads us to thinking that the new LLM might have indeed improved from a technical standpoint, but these improvements do not reflect in practice due to the strict guardrailing policy. In the case of the LTM Agents, going back to the previous 1106 version of GPT-4 gives us an extra 4.5 points.
On the winning side, LTM Agent 1 aces the delayed and instruction recall tasks, a feat that no other agent achieves. Also, the ability of locating the memories along the time axis gives these agents a higher chance in tasks with a strong temporal aspect, like the Jokes task. On the other hand, we have noticed some cross-talk in multi-needle tasks, like Name List and Jokes, and the agents tend to give constant answers in ChapterBreak.
Apart from this, other failure modes point us to things that could be improved in our benchmark. We have identified some slightly ambiguous questions in the Instruction Recall tasks, and a couple of dubious evaluations in the Restaurant task, in which we might have been too strict in the scoring and let the agent fail for a simple choice of words. Additionally, we spotted some answers in the Sally Anne task that scored negatively but were technically correct. When asked about the location of a specific object, the agent was expected to answer with “treasure chest”, but it answered with “porch”, which is technically correct because the treasure chest was in the porch.
Benchmark 1 and Benchmark 2
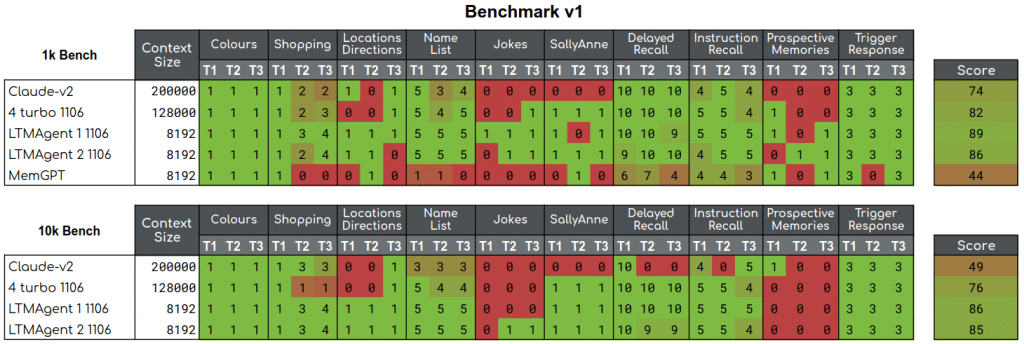
There were changes to how the Benchmarks were performed between version 1 and version 2. In short, benchmark 1 was performed as a series of episodes, where a single episode contained one test from each of the test datasets. Between each of these episodes was a full reset of the agent, wiping the context and any memories that the agent had.
In benchmark 2 that structure was changed so that the test consisted of a single conversation. Instead of wiping the conversation and memories ourselves, the agent was told that it should forget the contents of the previous test.
To compare the effect of this, we have picked out models that were tested on both benchmarks. These are LTMAgent1 and LTMAgent2 which are agents using GoodAI’s LTM implementation and GPT-4-1106.
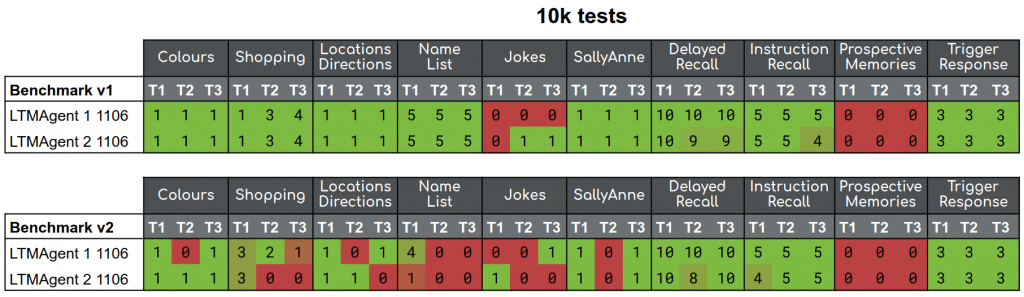
Extracting these results into a comparative table, we can see that the character of the shopping and namelist results have changed dramatically. These tests have only changed in their specific content between the two benchmarks, but there has been a steep decline in the scores. We know that since the semantic memory of both agents is passive, the reset message given to the agents won’t perform any cleaning. So it’s up to the agents to either take a note in their scratchpad (in the case of LTMAgent 1) or be lucky enough to retrieve the reset messages and associate them with other retrieved memories.
This extra challenge shows that the agents need some method of resolution for old or outdated memories. Ideally without removing those memories entirely, as that would harm episodic or historical memories. And while the LLMs don’t have any LTM systems, these tasks also show that they encounter challenges with correctly associating the reset messages with information given to them previously.
Conclusion
In this blogpost, we have introduced our new tests and have gone over the results of the GoodAI LTM Benchmark version 2, and taken a look at the models and tests in detail. We have seen that the latest OpenAI model, GPT-4-0125, is less performant than the previous 1106 model. It appears to have been tuned to be very defensive of user data, which while a good thing, harms its performance in the tests by not wishing to restate information given to it by the user.
The jump from multiple discrete conversations to a single conversation puts the onus of resetting (i.e. archiving or otherwise disqualifying old memories) on the agent, instead of us doing it manually. None of the agents that we have tested here have this process perfected yet. In the namelist task especially, there are significant data leaks from one test to the next. Conversely, there are cases where the reset message is retrieved or attended to along with the current pertinent information as in the case of the delayed recall task for LTMAgent2-1106 on the 10k benchmark. These changes have overall made the benchmark a much harder challenge for the agents.
While Claude-3-Opus posts the most impressive scores, this is accompanied by an equally impressive cost. The LTMAgent models achieve 92% of Claude’s performance with 6% of the cost. This is mostly down to the LTMAgents using only 8k tokens of context, versus Claude’s 200k. The LTMAgents are using GPT variants, so it would be useful to see how well Claude itself pairs with the LTM.
The tests themselves are not perfect and we have identified a number of ways they can be improved. Most notable of these is the prospective memory task. All of the responses to the task in Benchmark 2 have expressed confusion about what the agent should do. A selection of other tests have some clumsy phrasing (Instruction Recall), are too easy (Trigger Response), or have uneven difficulty (SallyAnne). We will constantly refine these tests to keep them useful for the GoodAI LTM Benchmark version 3 and beyond.
Get involved
Join our Discord!
Our Benchmarks and results are freely available to all on github. If you have a model that you want to include or an idea for a test, then please send us a pull request.
Also released by us is a personal assistant Charlie Mnemonic. Stay tuned for how well it performs on the benchmarks!





Leave a comment