
Authors:
David Castillo, Joseph Davidson, Finlay Gray, José Solorzano, and Marek Rosa
Note: This post describes a version of the blogpost where some of the details have been outdated. See the second and third posts for more up to date descriptions of the benchmark.
Summary
As part of our research efforts in the area of continual learning, we are open-sourcing a benchmark for testing agents’ ability to perform tasks involving the advanced use of the memory over very long conversations. Among others, we evaluate the agent’s performance on tasks that require dynamic upkeep of memories or integration of information over long periods of time.
We are open-sourcing:
- The living GoodAI LTM Benchmark.
- Our LTM agents.
- Our experiment data and results.
We show that the availability of information is a necessary, but not sufficient condition for solving these tasks. In our initial benchmark, our conversational LTM agents with 8k context are comparable to long context GPT-4-1106 with 128k tokens. In a larger benchmark with 10 times higher memory requirements, our conversational LTM agents with 8k context achieve performance which is 13% better than GPT-4-turbo with a context size of 128,000 tokens for less than 16% of the cost.
We believe that our results help illustrate the usefulness of the LTM as a tool, which not only extends the context window of LLMs, but also makes it dynamic and helps the LLM reason about its past knowledge and therefore better integrate the information in its conversation history. We expect that LTM will ultimately allow agents to learn better and make them capable of life-long learning.
Motivation
At GoodAI, we are developing LLM agents that can learn continually from the interactions with the user and the environment. Our goal is to create agents that are capable of life-long learning, which means that they are constantly gathering knowledge from every new experience and leveraging all past knowledge to act and learn better in the future. In the past we have organized the GoodAI Challenge, specifically the Gradual Learning round in 2017, to stimulate ideas on continual learning.
While pursuing this goal, we quickly realized that we needed a way to objectively measure our progress on LLM agents’ ability to learn continually. Very often we found ourselves trying different solutions to the same problem and not knowing which one to choose. The methods were usually different, but the results felt equivalent or not significantly different. In addition to this, most existing benchmarks fell short for our purposes because of a strong focus on testing LLM-specific capabilities, like mathematical reasoning, instruction-following abilities, or being centered around testing specific methods or tools; such as vector databases, prompting, information placement within the context, or performance in question-answering tasks based on static memories or factual knowledge.
In short, most benchmarks focused either on aspects that were LLM-, method- or implementation-specific, and we wanted to have something that we wouldn’t need to throw away and rewrite from scratch in the future. On the contrary, we needed a frame of reference that was capable of standing the test of time and that would evolve as we discovered new caveats in our own agents and translated them into new goals to achieve. A stable benchmark for a constantly-changing agent: an incremental, continual, and conversational benchmark.
For these reasons, we developed the GoodAI LTM Benchmark, a framework that can test conversational agents’ abilities to learn and adapt in realistic scenarios and over long periods of time. This benchmark differs from other question and answering benchmarks in these main aspects:
- It is purely conversational. As long as your agent can send and receive messages, it can go through our tests. Try it! We even have an interface for humans!
- Information is dynamic. Information changes throughout the test (e.g. the user’s name, their favourite colour…) and the agent will have to integrate all these changes in order to ace the test.
- Not implementation specific. You will be testing your agent’s delayed recall, prospective memory, ability to reconcile conflicting information, ability to integrate information across long conversation history, etc. How does your agent work? We don’t care.
- It is realistic. All tests take place in the context of a conversation between the agent and a virtual tester, in which the agent has to perform multiple interleaving tasks, spanning across time and messages.
Background
Large Language Models such as LLaMA1https://arxiv.org/abs/2302.13971, Mistral2https://arxiv.org/abs/2310.06825, Claude3https://www.anthropic.com/ or GPT4https://arxiv.org/abs/2005.14165 have taken hold of the popular discourse surrounding AI progress. LLMs operate by taking some input text, which can be a conversation between a user and the LLM itself and is often called the context. Whenever the LLM runs, the information in the context is combined with the information encoded into the weights of the LLM. What the LLM produces is more text that is appended to the current context. The LLM therefore iteratively produces text, going roughly word by word in an auto-regressive manner until it has finished generating.
In order to generate a response, the LLM only has access to the knowledge encoded in its weights and that is present in the input context. Because it is (currently) impractical to frequently retrain the weights (known as finetuning), as users the only influence we have to affect the knowledge of the LLM is through the context. However, due to current constraints, the context window itself is finite so a sufficiently long interaction can push old information out of the context, effectively making the LLM “forget” what has been said to it in the past. There are other issues that can occur with just relying on the context, including that of the LLM not being able to see information in its context5https://arxiv.org/abs/2307.03172, struggling with spread-out but dependent information, and expensive LLM calls with large contexts (see our results below for GPT4 and Claude).
The straight-forward fix for this finite context is in connecting the LLM to an external system that is able to keep a longer-term record of the information provided, and to retrieve potentially useful information and provide it to the LLM during generation. There are many ways to accomplish this. Some techniques rely on extending the LLM’s architecture6https://arxiv.org/abs/2306.07174, but they generally require more training or fine-tuning of the interplaying parts. A different approach avoids further training by using the LLM’s context as an information entry point. This approach is generally known as Retrieval Augmented Generation (RAG)7https://arxiv.org/abs/2005.11401, and it usually builds on top of some form of semantic database and search engine, but the process by which it handles the memories can be of arbitrary complexity8https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6. Thanks to these methods, LLM agents are capable of exhibiting Long-Term Memory (LTM) skills, through which they are able to recall much older information, by far surpassing the possibilities offered by the standard fixed-size context. Additionally, it also serves to focus the attention of the LLM on the information thought by the retrieval mechanism to be important to perform the task given to it.
But being able to remember a large number of things is not equal to having a great memory or making the most out of that information. In real (continual-learning) scenarios the amount of information builds up rather quickly and the agent is soon facing conflicting memories and complex instructions that depend on having understood and reflected upon past experiences9https://arxiv.org/abs/2304.03442. We therefore emphasize the importance of information integration as a key element of continuous learning, which means that the agent is not only expected to remember isolated pieces of information, but also to establish connections between them and its current knowledge, weaving them into a cohesive network of understanding, and updating, reinforcing and expanding upon existing patterns.
Just as in human cognition, where learning new mathematical concepts can enhance problem-solving abilities in seemingly unrelated domains, an agent capable of information integration can leverage its recently-expanded knowledge base to navigate novel challenges with greater efficiency and insight. In the context of life-long learning, agents should be expected to deal with an infinite-growing corpus of complexly connected and constantly changing information on a daily basis.
However, most of the currently existing benchmarks that are intended to test an agent’s memory take a white box approach and focus on searching preprocessed data. This includes benchmarks like The LlamaIndex evaluation tools10https://docs.llamaindex.ai/en/latest/module_guides/evaluating/root.html# and datasets like Document QA11https://huggingface.co/tasks/document-question-answering, in which many test instances can be classified as examples of the “needle in a haystack” problem. This is like having someone hand you a notebook full of information before the tests start, and your job is to go through the text and find where the answer is, but without having to deduce much from it or change your way of thinking.
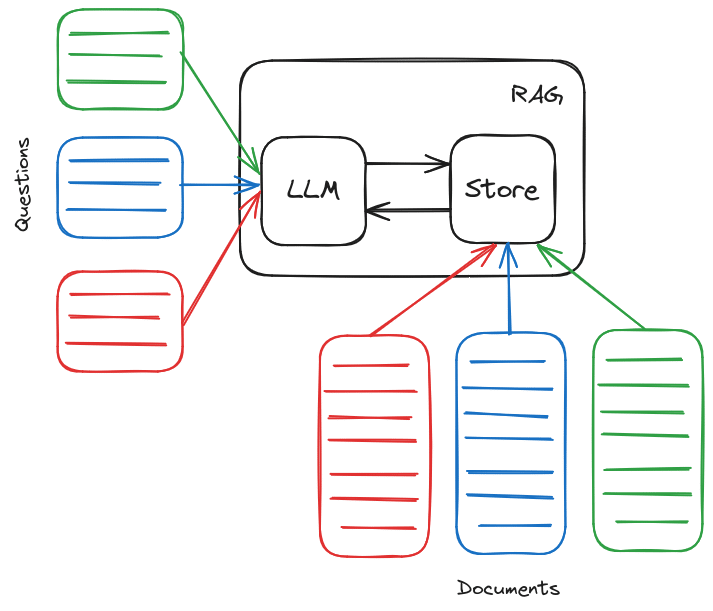
Current RAG Benchmarks with QA over documents.
The GoodAI LTM Benchmark
At GoodAI we have specific visions and use cases for agents with LTM. We envision agents that don’t just digest and perform question-answering on documents, but will also have access to a potentially messy “lifetime” of conversation and actions. These agents would not only read from knowledge bases, but also contribute to their own memories throughout their lifetime, logging interactions with the user or other agents, remembering instructions, conversations, and feedback.
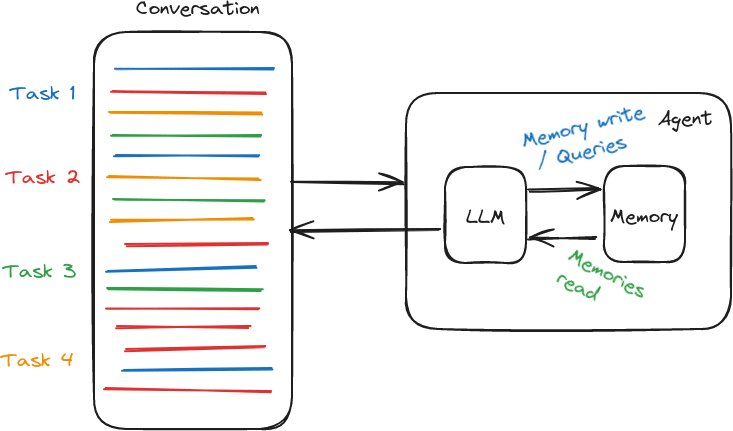
The GoodAI LTM benchmark that tests in a conversational manner with knowledge intermingled with questions in a long conversation. Testing a simple agent with LTM.
The Testing Procedure
The testing procedure entails a conversation between the agent and a virtual tester. Each test is structured as a script with informative statements, spaced regularly with Distraction Segments which are “filler” statements that do not relate to the current test. At the end of the script, there is a question that is asked and the test is evaluated based on the answer from the agent. The purpose of the distraction segments is to spread these informative statements across the context and put distance (in terms of tokens) between the informative statements and the final question. We call the total token distance between the relevant statements and the question as the Memory Span, which represents how many tokens into the past the agent would have to integrate information from in order to answer the question.
Practically, we interleave the tests as shown in the diagram below. This means that what is a distraction segment for one test, is at the same time a compound of informative statements and questions, along with their corresponding agent responses, for other tests. This improves the quality of the distraction segments while minimizing the amount of tokens wasted in tasks that are a mere distraction and will not be evaluated.
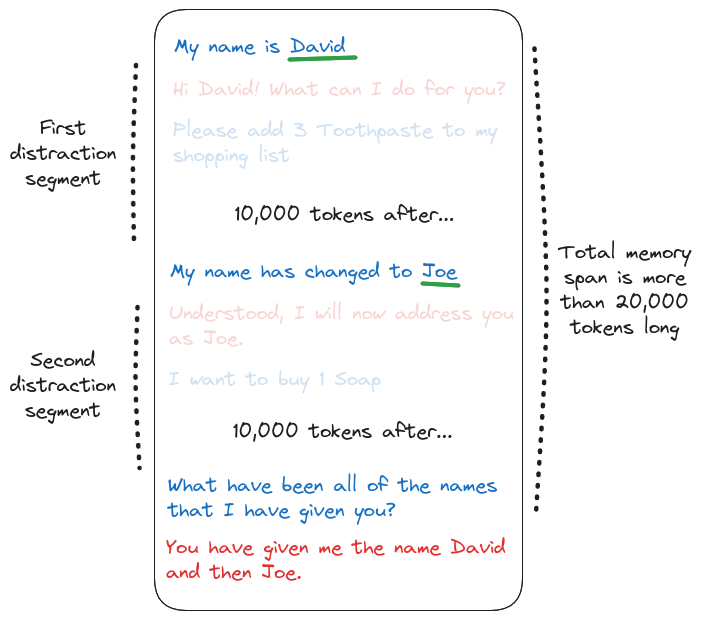
Figure. A visual representation of how the distraction segments work. Once the length of the distraction segment is set (here is 10,000 tokens), the virtual tester will make sure that the number of tokens separating relevant pieces of information is at least that. The memory span that the agent will need to consider for its answer depends on the task, but it is proportional to the number of relevant pieces of information given.
Most tests are defined in a way that makes them trivial to evaluate, which lets us use simple functions for that purpose. For example, if the final question is “How many times have I changed my name?”, and the answer is 3, then we can just look for the string “3” or “three” in the response. In other cases, the responses require a more nuanced analysis, but still we make sure that the evaluation can be performed by GPT-4. In addition, and for improved robustness, we ask the evaluator to present the relevant information in JSON form, which is a known strength of the latest GPT models and allows us to perform some of the logical parts of the evaluation programmatically, instead of via the fragile logical capabilities of the LLM.
Test Scenarios
We have talked long about our vision for long-term memory, which isn’t just about remembering past information, but about connecting current situations with any past relevant data, recontextualizing current and past events. Additionally, there are many challenging elements and confounding variables that are in play, like conflicting information or dealing with several tasks within a limited time interval.
For our LTM benchmark we have taken inspiration from psychology in order to build meaningful and organic test scenarios, which abstract away from the agent’s implementation and focus on the agent’s abilities to recall and effectively leverage past information. Here we show three types of memory skills that we test and the corresponding example scenarios that we use to evaluate them:
- Information integration. According to information integration, an agent must not only be able to recall pieces of information, but also to put them together and consider the actual implications of those pieces being interconnected. We test this ability by having the agent keep track of a shopping list, which we update at regular but spaced intervals. In order to solve this task, the agent needs to know the current state of the shopping list, which implicitly requires it considering all updates in the right order. Any missed step in the series of list updates will probably result in an incorrect outcome.
- Episodic memory. This memory skill helps with the organization of memories based on when they happened e.g. 5 minutes ago, yesterday or last week. It implicitly requires the agent to be time aware. A way in which we test it is by telling the agent a joke every now and then, and finally ask the agent what was the joke that we told it so much time ago. We found this test to be quite challenging for most agents, since time awareness often goes unnoticed in standard implementations.
- Spatial memory. It is the kind of memory that is used for associating information to a position in some predefined space. Spatial memory is key for navigating spaces, interpreting maps, etc. In one of our tests, we give the agent a series of relative locations in a fictional town e.g. “In the center of the town there’s a church”, “Two kilometers to the east of the church there’s a school”, etc, and then we ask it for directions to get to a specific place.
You have probably noticed that testing for spatial memory implies to some degree testing for information integration too. This is expected and it happens frequently, although we always try to include isolated tests when possible. However, given that we focus on testing abilities and not implementations, essential memory skills will inevitably be part of the more complex ones, which is in fact a key aspect of continual learning.
Want to read more about the tests involved in the GoodAI LTM Benchmark? Check out the public repository.
Metrics and evaluation
The GoodAI LTM Benchmark is composed of a series of tests, which originate from different datasets that evaluate different aspects of the agent’s LTM capabilities. Each test task can have its own scoring procedure, but each of them will always result in a number of score points achieved, out of the total score points of the corresponding test. While testing, we also capture several metrics that are useful for assessing different characteristics of the agent, like the generation speed, average response length and overall cost. The cost is usually computed for API calls, but it can also include costs derived from local computation, like GPU-derived energy consumption (see more in our agents interface documentation).
These are the metrics that we extract from benchmarking a single agent:
- Score. (In points) Each test gives a different amount of score points, which depends on the number of elements that it evaluates.
- Average Test Accuracy. (In percentage) From each test we take the score achieved and divide it by the maximum score possible for that test. We then average all tests’ accuracies together. This can be viewed as an overall uniformly-weighted score.
- GoodAI LTM Score. (In LTM Score Points) It is computed from the number of tokens that separate the relevant information from the final question in each test. In every case, this distance is weighted by the accuracy achieved in the test.
- Speed. (In completed tests per hour) How many tests, on average, the agent completes within an hour of running the benchmark.
- Cost. (In USD) Overall cost of running the agent for the whole benchmark.
- Verbosity. (In tokens) The number of tokens that comprise the complete benchmark log. Larger responses will increase the value of this metric.
Additionally, we track the total memory span for each test. A benchmark can be made easier or harder by configuring the minimum length of the distraction segments. This will influence how far apart the informative messages are in the conversation, and it will ultimately determine the absolute memory span that the agent will need to face during testing. Since there is some variability in how the conversation happens, we keep a record of these distances and show the memory statistics in the final report.
Our system generates self-contained HTML reports containing detailed information about every test in the run, including logs, explained evaluations and records of the resulting memory span for each test. Additionally, a comparative report can be generated after two or more agents have been run. Comparative reports are optimized for a quick visual interpretation in the comparison of different agents.
Benchmark 1 Results
We run Benchmark 1 consisting of 10 different types of tasks, with 3 tests from each type, for a total of 30 test scenarios. Between statements in each script, there is a distraction segment, which is a series of messages unrelated to one test, but potentially related to other tests. For this benchmark, we test with distraction segments of 1000, and 10000 tokens. Keep in mind, however, that the final memory span for a test can be much larger. We run the tests as three separate conversations of 10 tests in order to avoid any conflicts arising from running two tests of the same type at the same time.
In these tests, we are looking at conversational models. We benchmark two of our agents with LTM capabilities (LTMAgent1 and LTMAgent2) against another LTM-capable implementation: MemGPT12https://memgpt.readme.io/docs/index. We also compare against baseline LLMs of gpt-4-1106-preview (colloquially known as “gpt-4-turbo”) with a 128,000 token context, and Claude-2.1 from Anthropic AI with a 200,000 token context.
Distraction Segments of 1,000 Tokens
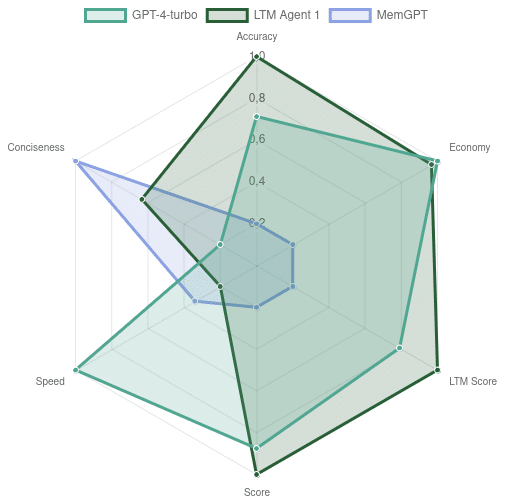
Figure. Comparative chart between the agents LTMAgent1, MemGPT and GPT-4-1106. GPT-4-1106 has a maximum context length of 128,000 tokens, while the other agents use a maximum of 8,192 tokens in their internal LLM calls.
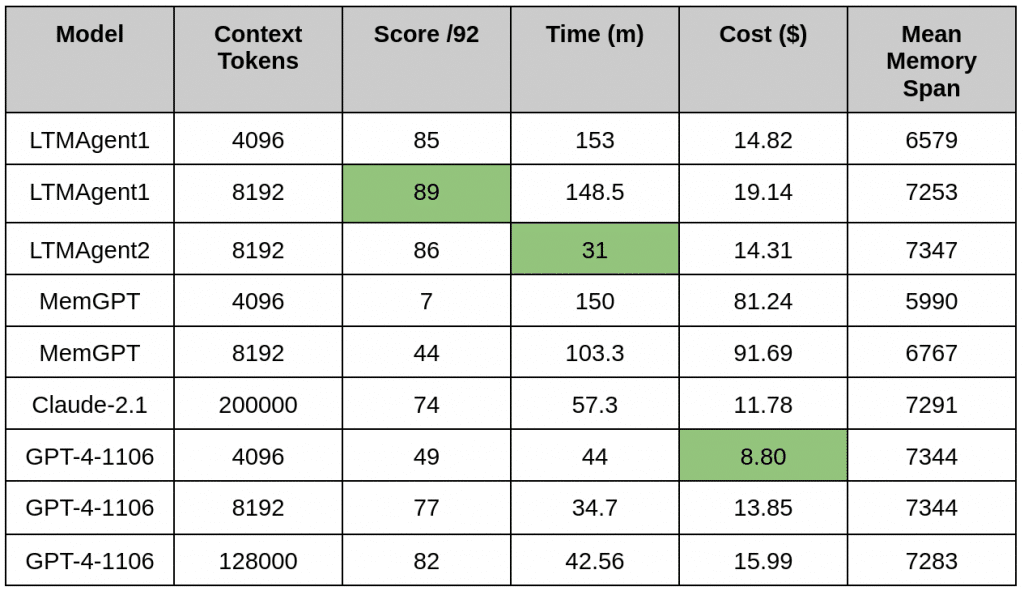
This benchmark uses distraction segments of 1000 tokens, so there are at least 1000 tokens between statements in the test script, and between the final informative statement and the question. In this test, the average conversation length is around 13,000 – 14,000 tokens.
GPT-4
Looking at the GPT4 results, we can observe that the scores correlate with the number of tokens permitted in the context. The memory span of some tests is short enough to fit into the context window of 4096 and 8192, whereas some questions fail because they fall out of the window.
Interestingly, the 128k context agent does not obtain full marks on the test. An issue for this which is common for all the pure GPT models is in the episodic memories. We do not supply a timestamp to the the models as to when a piece of information was given, so when we ask for one from a specific time, the GPT model cannot reconcile that timestamp with the context and randomly chooses a statement that it was given previously in the conversation, or apologizes for not being able to answer the question.
Claude
Claude is an LLM supplied by Anthropic, with a large context of 200,000 tokens. In this benchmark the performance is the lowest of the theoretically capable models, excluding MemGPT. One of the failure points for the agent compared to GPT is in the SalllyAnne tests. Whilst the integration of the information at the point of questions appears correct, after each line of the script, the agent expresses confusion about what is going on and desiring more context.
These results line up with the popular discourse on the capabilities of Claude versus those of GPT4. The GPT agents that can answer the tests are more accepting of the facts as given and integrate them correctly, where Claude tends to integrate the confusion it has for the statements.
LTMAgent1
LTMAgent1 is an agent that leverages an early version of our LTM-system, which is a work in progress of our LTM research team. Both versions of the agent are using GPT-4-1106 as well as the LTM, and are well above the baselines set by the corresponding GPT-4 runs. Despite using half of the context, LTMAgent1-4096 is only one point short of LTMAgent1-8192. Crucially, they also surpass the score of the 128k GPT4 agent, which is an indicator that larger contexts do not necessarily translate to better performance, and that a more focused context with fewer distractions is superior. These memories take time to organise however, which results in the running time of LTMAgent1 being triple that of the GPT agents.
LTMAgent1 operates as follows: User and agent interactions are chunked. Chunks are associated with embeddings and are added to a queue with 50% overlap. On retrieval, chunks are expanded up to at least 96 tokens and up to the nearest line break. Retrieved excerpts – or expanded chunks – are listed in the prompt in chronological order, with timestamps. Excerpts are allowed to occupy half of the LLM prompt. In addition, an internal LTM prompt generates query candidates and a JSON object containing information provided by the user or that the user might be expecting the agent to keep track of. The JSON object is akin to a scratchpad or working memory.
LTMAgent2
LTMAgent2 is a pared down version of LTMAgent1 and is completely semantic. As with LTMAgent1, the semantic memory is chunked with overlaps and expanded on retrieval. Where the agents differ is in the lack of this second internal query generation, and the JSON scratchpad.
The results for LTMAgent2 are three points lower than that of the comparable LTMAgent1. From the reports, the test results show interesting differences between the agents. In the SallyAnne test, LTMAgent2 actually outperforms LTMAgent1 in its information integration, but it similarly falls short in the shopping list test (a test where having a scratchpad seems to be useful), in locations-directions, and the jokes. Further investigation will be conducted to ablate the functionality of LTMAgent1 to see if its query generation helped, or if it served to confuse the agent when integrating the information of the SallyAnne test.
MemGPT
The MemGPT agent is a conversational LTM agent much like the LTMAgent1. However, this benchmark shows, performing poorly whilst being extremely expensive to run. Examining the paper, and looking at the default context reveals that MemGPT is an actively managed memory where the agent makes function calls to add and search memories, as well as send messages to the user.
The reasons for failure are threefold:
- The agent requires a lot of tokens in the system prompt + examples (~2000) so that it knows how to send messages to the user, but that leaves a smaller proportion of its context for retrieving and using memories.
- Because the memory is actively managed, more of the conversational context is used up by the agent performing internal actions like updating or retrieving from memory, this both requires a GPT-4 call, and adds messages to the context, filling it further.
- When culling the context, if memories in which the agent sends a message are removed, then it sometimes will forget that it needs to send messages.
Most failures in the MemGPT evaluation are linked to empty responses to the questions, because the agent forgets that it needs to send them. In our testing, we attempted to limit the size of messages to the agent to 300 tokens, so that when the agent truncates the context, it will have more smaller messages that can be removed, rather than fewer larger ones. But this approach both seems to be ineffective, and costs more in the form of API calls.
Distraction Segments of 10,000 Tokens
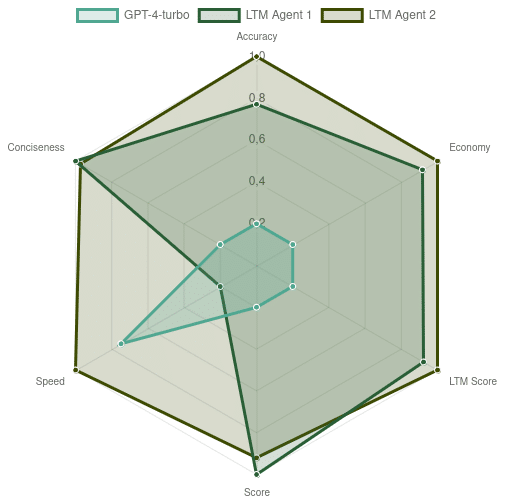
Figure. Comparative chart between the agents LTMAgent1, LTMAgent2 and GPT-4-1106. LTMAgent2 sacrifices some performance in favour of a greater generation speed, which is hurt by the large amount of context tokens in the case of GPT-4.
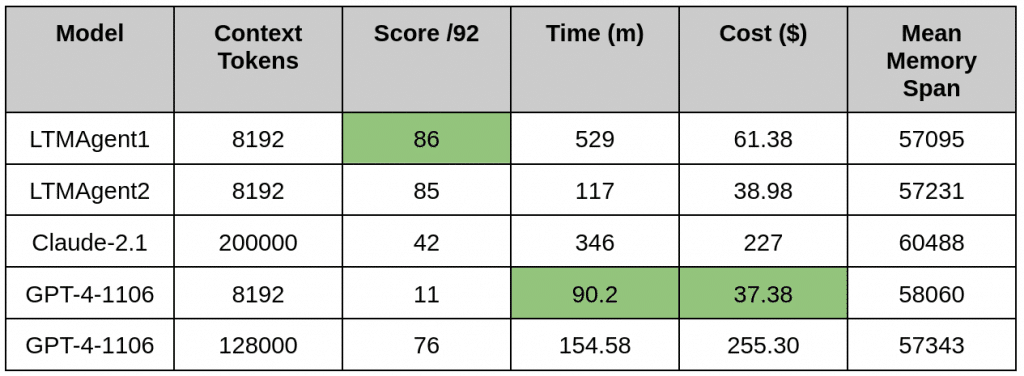
In this second benchmark, we have increased the size of the distraction segments to 10,000 tokens, which means that the question and the information relevant to answering it will be at least 10,000 tokens apart in the conversation. The average conversation length for these tests are between 112,000 – 115,000 tokens on average. With the outlier being Claude which we will discuss below.
GPT-4
We can see that longer distraction segments are already too much for the GPT-4-1106 LLM constrained to 8k tokens, which is expected because most of the time the relevant information will already be out of context when the question arrives. However, the score drops for its unconstrained version too, which is a bit surprising because the huge context size of GPT-4-1106 is enough to keep all relevant information, despite the increased distraction segments. Each conversation that the model has tops out at around 113,000 tokens, which implies that the amount of distraction segments or level of dispersion in the context is too much for the attention mechanism, and so it misses key information when trying to answer questions.
Claude
The performance of Claude degrades sharply in this test when operating with many more tokens than that of the 1k benchmark. It appears that the same issues that the GPT models face are replicated here. From the report, the agent appears to miss blocks of facts in the delayed recall tests, and confuses characters in the SallyAnne tests with the names of the user in the namelist tests.
Due to API constraints, we had to resume the benchmark a few times, and therefore leverage the interleaving of tests to a lesser degree than we did for other agents. This resulted in a final conversation length of 424,275 tokens, despite the tests’ memory spans being equivalent to those used for other agents.
LTMAgent1
The score for LTMAgent1 goes down by 3 points, which is much less of a decline than that of the purely LLM-based agents, and highlights the qualitative difference between an LLM with long-context and an agent with diverse LTM capabilities. In addition, the fact that all scores decrease suggests that there is an implicit difficulty in the span that the agent’s memories spread across.
LTMAgent2
As we discussed before, the main difference of this agent with respect to LTMAgent1 is that it does not use JSON, or rewrite the memory query. Observing the reports, there maintains a complex intersection of tests that succeed. For example, LTMAgent1 fails on all of the jokes, in one case hallucinating a new joke that it was never told. LTMAgent2, gets 2 of three correct 3, but it similarly falls short of LTMAgent1 in the delayed and instruction recall tests.
Overall, we observe that it only loses one point to LTMAgent1, while achieving great improvements in terms of speed and cost. These results indicate that the importance of dynamic scratchpads is lower than expected, but also that the main contributing factor to our LTMAgents’ performance might be related to how the memories are presented to the LLM (e.g. with timestamps and in chronological order).
Conclusions
We have presented the first version of the GoodAI LTM Benchmark and provided some initial benchmark results of the GoodAI agents LTMAgent1 and LTMAgent2, MemGPT, and plain LLM agents. This benchmark differs from contemporary RAG benchmarks in that we do not implement the tests as questions and answers over documents, but as a continuous conversation between a virtual tester and agent, where questions for one task are intermingled with key information for other tasks. We believe this is a challenging environment, for an agent would need to have a highly dynamic memory which is kept up to date in order to achieve a high score.
These initial results have also shown failure modes of large contexts. Even if a model can fit all of the relevant information in its context, if that information is dispersed across the context the model can have difficulty with integrating it to supply an accurate answer. Agents with an LTM appear to have the potential to better collate this dispersed information through their memory mechanisms.
We have also discovered that there is an intrinsic difficulty in longer conversations, as all agents seem to struggle an extra bit on those, and that there is still plenty of work to do in the area of semantic retrieval, which is suggested by a difference in performance between our LTM Agent baselines. These results highlight the importance of the way that information is presented to LLMs when their functionality is augmented by an external system.
Future work
This is intended to be a living benchmark. We will use it internally to prototype agents with continual learning capabilities and add more tests as we discover failure cases, or desirable memory behaviours. We will also add new agents/models, if we find them interesting and it is practical to do so, in order to maintain a picture of the LTM landscape.
Aside from the above, we have plans to:
- Fit the whole benchmark into a single conversation. Currently, we sometimes force reset the agent’s memory to avoid interference between tests, but we are moving towards a version in which we just ask the agents to forget things instead, or explain the situation to it and let it take the pertinent measures. Our goal is to keep everything as part of the same very-long conversation (e.g. teach it the content of one shopping list, test it, then say to forget the content, and teach it the second shopping list, etc, all as a natural conversation between the virtual tester and the agent).
- Add more datasets, especially focused on advanced LTM properties. Some examples are:
- Large-scale information integration. From figuring out what led the main character of a novel to commit crime, to finding the root cause of a zero-day exploit among the thousand lines of code of an operating system, there are a vast number of everyday problems that exceed the capabilities of simple semantic retrieval. Very often, these questions require one to read one or more books, analyse their content, think about the implications of the recently acquired knowledge, establish connections to previous knowledge, etc.
- Conflicting memories and apparent contradictions. An issue with today’s agents is that most of them rely on LLMs with a fixed set of weights, and these weights encode knowledge that is potentially subject to change. However, it has been observed that LLMs are very reluctant to alter their core beliefs, no matter how much information they receive pointing in other directions. Our plan is to first focus on having the LLM accept knowledge that contradicts its knowledge from training, which is present in its weights. Secondly, we want to address new facts that contradict knowledge consolidated in the agent’s LTM.
- Complex instructions. We have observed that agents often struggle to follow instructions when there are many of them, or when these instructions are cumulative and build on top of other instructions. These are issues that have been often associated with limitations of the LLMs, but they are undoubtedly related to continual learning and we are committed to the generality of our benchmark. More focus will be placed on teaching new skills, including instructions, rules, and behaviors, to address these challenges.
- Add more contemporary RAG benchmark tests. While initially we have aimed to test the features that current benchmarks don’t test, we also want to test those standard features, despite in a less implementation-specific way.
- Set a web endpoint for people to take a chance at our LTM benchmark. Interactions here might contribute to a human-level baseline and will help us better understand the challenges of continual learning.
- Expand our baselines. We would like to include benchmark results for more and diverse agents, such as the LTM possibilities of LongMem13https://arxiv.org/abs/2306.07174 and LangChain14https://www.langchain.com/. We are also interested in seeing how web versions like ChatGPT would score.
- Revisit our Gradual Learning Challenge. While the original challenge was somewhat tailored for reinforcement-learning agents, its core motivations and vision were very much aligned with the purpose of this benchmark. By testing gradual learning, we test the ability to use previously learned skills to more readily learn new ones.
- Build a community around agents with LTM. We are well aware that the best way to foster progress is through open-source projects and collaboration. We aim to keep the benchmark in constant evolution, adapting it to the latest challenges and making it the best tool to help researchers explore the frontiers of what’s possible now in terms of LTM and continual learning, and we want the community to be an active part of it. Please visit us in our Discord!
- Test much longer memory spans. In order to have agents capable of life-long learning, we must keep in mind that anything that is not able to deal with an infinite-growing set of memories and knowledge is not an option anymore, and in order to test such scenarios we will need to create conversations that span more than a few thousand tokens. We will need to benchmark these agents within conversations that are millions of tokens long.
- Go multi-modal. Even if communicating only through text, humans would soon find a way to send links to large documents, images, audio, video… We want to explore the possibilities along this direction.
- Go multi-lingual. Benchmarks that test for agential skills or abilities are all in English, and while it is taken for granted that the performance will be equivalent in other languages, such things have not been tested yet. We plan to test whether agents perform as well when we talk to them in English as when we do in Slovak, Spanish, Hungarian…
Get Involved
All this code and data is licensed under MIT.
This initial version of the benchmark is available here, we will be continually adding tests to it as our requirements for these online LTM systems mature. If you have an LTM or RAG system that you think could perform well on these tests, feel free to implement our interface and make use of it. Similarly, if there is an aspect of memory that you think should be tested, please create an implementation for it and send us a pull request.
We are well aware of the costs of running extensive benchmarks like this one, so we are also sharing all benchmark specification and result files with you so that you can compare those models with those of your own. We intend to do this for subsequent releases as well, tuning the tested feature set to match the latest discoveries and challenges.
Reach out to us if you are interested or want to collaborate on LTM systems and continual learning:





Leave a comment